
F12查看网页源码,开头就注释这zip,里面的其他注释没有用。
将链接最后的.html改成.zip,得到一个压缩包;
压缩包里有多个文本,内容都是Next nothing is XXX,想到是和第四关一个套路
查看压缩包里的readme.txt,得知从90052.txt开始
import re
import zipfile
# 匹配末尾数字的正则
pattern = re.compile('Next nothing is (\d+)')
nothing = '90052'
# nothing为数字就继续循环
while (nothing.isdigit()):
# 打开文件
with open(f'./channel/{nothing}.txt', 'r') as file:
line = file.readline().strip()
print(line)
matchObj = pattern.search(line)
# 没有匹配到就跳出循环
if matchObj:
# 修改nothing的值
nothing = matchObj.group(1)
else:
break
输出Collect the comments.
python有个自带的zipfile包用来处理压缩文件,其中每个文件都提供一个comment属性,这里的意思就是按照之前的next nothing顺序,输出每个文件的comment属性
import re
import zipfile
# 新建ZipFile对象
zip_obj = zipfile.ZipFile("./channel.zip")
# 匹配末尾数字的正则
pattern = re.compile('Next nothing is (\d+)')
# 初始nothing
nothing = '90052'
# 用于存放每个文件comment的列表
comment_list = []
# nothing为数字就继续循环
while (nothing.isdigit()):
# 打开文件
with open(f'./channel/{nothing}.txt', 'r') as file:
line = file.readline().strip()
# -----这里也可使用split-----
matchObj = pattern.search(line)
# -----这里也可直接输出-----
comment = zip_obj.getinfo(f'{nothing}.txt').comment.decode('utf-8')
comment_list.append(comment)
# 没有匹配到就跳出循环
if matchObj:
# 修改nothing的值
nothing = matchObj.group(1)
else:
break
print(''.join(comment_list))
结果输出:
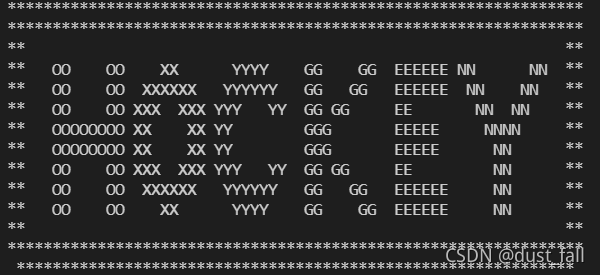
访问http://www.pythonchallenge.com/pc/def/hockey.html,网页就一句话it’s in the air. look at the letters.
回头细看上面的输出结果,发现H O C K E Y都是由另一个字母组成的分别是 O X Y G E N
得到通向第七关的地址是http://www.pythonchallenge.com/pc/def/oxygen.html