
目录
1.LSTM的问题
2.Seq2Seq的Attention
1.LSTM的问题
①梯度虽然部分解决,但并未100%解决,序列过长的话,还是会有梯度消失/梯度爆炸的可能。
②从应用的角度,一句话通常会有重点,因此我们需要考虑重点,而不是全都看。
2.Seq2Seq的Attention
核心是计算出每个隐藏层的权重。
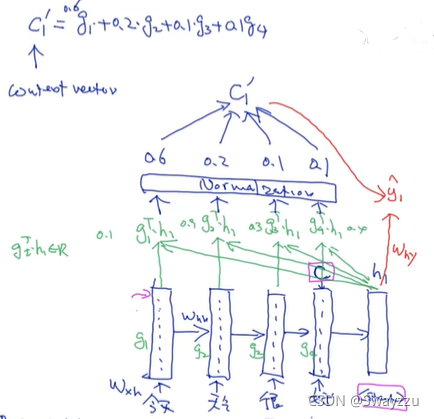
Encoder部分不变,主要变化在decoder部分。具体流程如下:
通过encoder部分,计算出最终的输出向量C,这个C是包含了一整句话全部的信息的。接下来:
①给到<start>标志输入给神经元之后,得到存储向量h1,假如没有attention,这里就该直接加上一个函数,对词的分布进行计算并且生成单词了。
②h1和前面的每一个存储向量g1,g2,g3,g4进行矩阵相乘,得到4个数字。这4个数字就相当于是权重了,但是并不是相加为一的。
③将这四个数字进行标准化,作为每一个模块的权重。比如分别是0.6,0.2,0.1,0.1。
④把权重和存储向量相乘,得到新的context vector,称为C1'
⑤在生成单词的时候,也使用这个新的context vector。一开始生成单词的时候依赖于h1这个存储的向量,但现在也会依赖于C1'。
原来是这样计算的:
中间是h1
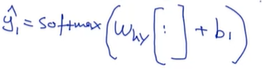
现在是这样计算:
中间是把h1和C1拼接在一起,计算完之后得到单词的分布。
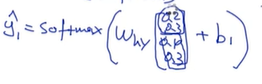
这样就生成了一个单词,那么这个单词就可以作为输入,加上C和h1作为输入,对下一个神经元计算,得到隐藏向量h2,之后同样也是把h2和前面每一个存储向量进行计算,得到权重,标准化,得到标准的权重分布,把权重分布和存储向量相乘,得到context vector C2,然后把C2和h1结合起来,求第二个单词的分布。
对于每一个单词都是同样的步骤计算。