
问题关键:past_key_value
- 模型的整体结构(由外到内)
- 最外层generation_utils.py之中的greedy_search调用模型解读
- t5Stack模型的解读
- t5block网络层中内容解读
- t5layerselfattention的解读
- t5layerselfattention+t5layercrossattention中t5layerselfattention代码解读
- t5attention的第一次运行
- t5attention encoder 第二次调用
- t5layerselfattention+t5layercrossattention中t5layerselfattention代码解读
- 第一次decoder部分的t5layerselfattention代码调用
- 第二次decoder部分的t5layerselfattention代码调用(这里的第二次为调用了6个encoder的t5layerselfattention以及decoder中的6个encoder的t5layerselfattention和t5layercrossattention内容)
- t5layerselfattention+t5layercrossattention中t5layercrossattention代码解读
- 第一次调用t5layercrossattention
- 第二次调用t5layercrossattention内容
通过之前对于代码的阅读,发现问题的关键就在于past_key_value参数的变化,导致输入不需要那么复杂的输入了,
模型的整体结构(由外到内)
模型的整体结构决定着数据的运转方向
模型整体的框架结构图
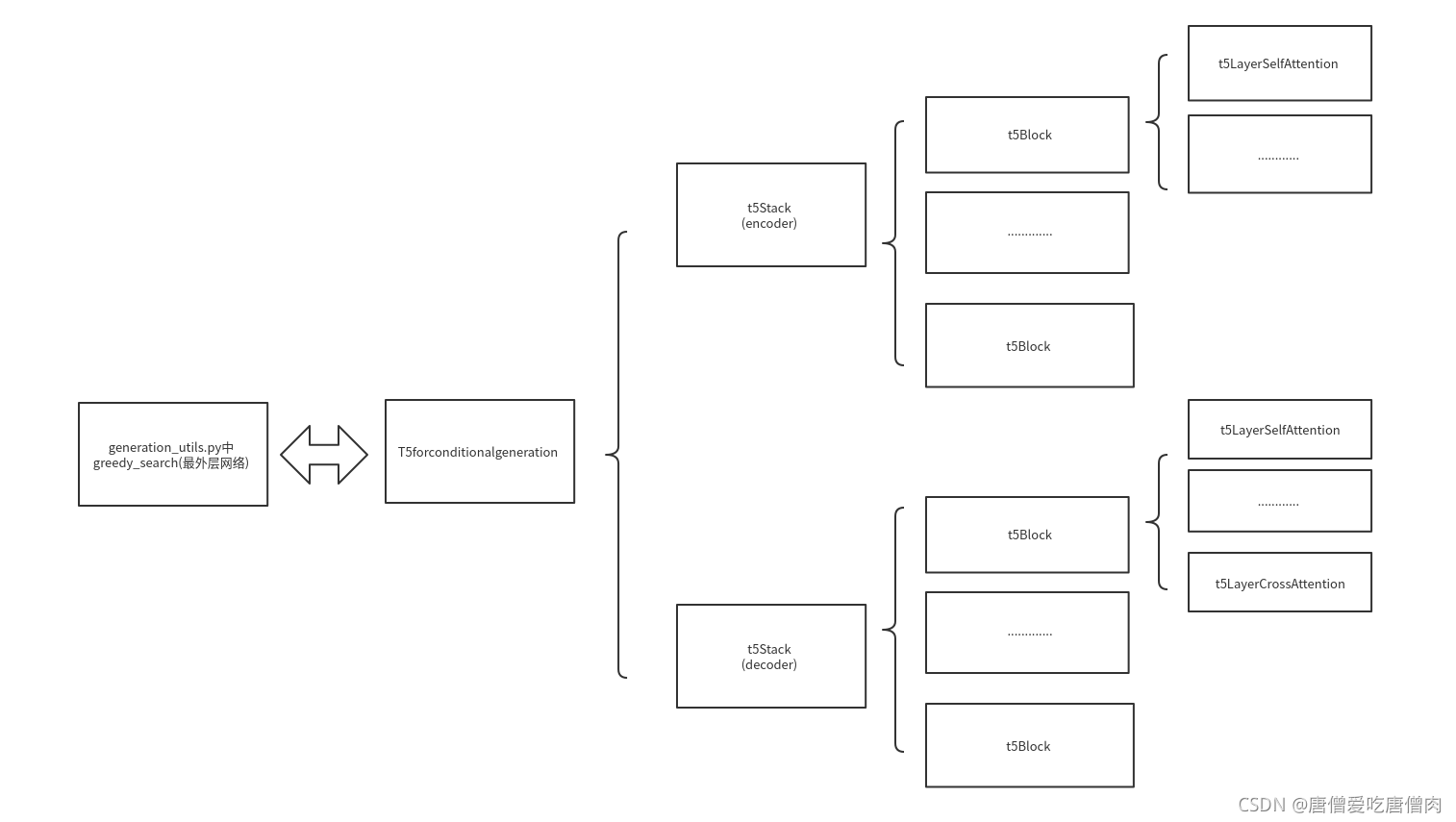
最外层generation_utils.py之中的greedy_search调用模型解读
while True:
if synced_gpus:
# Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
# The following logic allows an early break if all peers finished generating their sequence
this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
# send 0.0 if we finished, 1.0 otherwise
dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
# did all peers finish? the reduced sum will be 0.0 then
if this_peer_finished_flag.item() == 0.0:
break
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
if synced_gpus and this_peer_finished:
cur_len = cur_len + 1
continue # don't waste resources running the code we don't need
next_token_logits = outputs.logits[:, -1, :]
# Store scores, attentions and hidden_states when required
if return_dict_in_generate:
if output_scores:
scores += (next_token_logits,)
if output_attentions:
decoder_attentions += (
(outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
)
if self.config.is_encoder_decoder:
cross_attentions += (outputs.cross_attentions,)
if output_hidden_states:
decoder_hidden_states += (
(outputs.decoder_hidden_states,)
if self.config.is_encoder_decoder
else (outputs.hidden_states,)
)
# pre-process distribution
next_tokens_scores = logits_processor(input_ids, next_token_logits)
# argmax
next_tokens = torch.argmax(next_tokens_scores, dim=-1)
# finished sentences should have their next token be a padding token
if eos_token_id is not None:
if pad_token_id is None:
raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
cur_len = cur_len + 1
# if eos_token was found in one sentence, set sentence to finished
if eos_token_id is not None:
unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
# stop when each sentence is finished, or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
if not synced_gpus:
break
else:
this_peer_finished = True
这里的输入部分
input_ids = torch.cat([input_ids,next_tokens[:,None]],dim=-1)
得到input_ids = [0,644]
然后
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
这里估摸着参数为之前传下来的参数(目前只看了[0][0] = (1,8,1,64))
model_inputs['past_key_value'][0][0] = torch.Size([1, 8, 1, 64])
model_inputs['past_key_value'][0][1] = torch.Size([1, 8, 1, 64])
model_inputs['past_key_value'][1][0] = torch.Size([1, 8, 11, 64])
model_inputs['past_key_value'][1][1] = torch.Size([1, 8, 11, 64])
t5Stack模型的解读
t5stack的定义
def forward(
self,
input_ids=None,
attention_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
inputs_embeds=None,
head_mask=None,
cross_attn_head_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
进入t5stack类别之中查看内容
for i,(layer_module,past_key_value) in enumerate(zip(self.block,past_key_values)):
............
else:
layer_outputs = layer_module(
hidden_states,
attention_mask=extended_attention_mask,
position_bias=position_bias,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
encoder_decoder_position_bias=encoder_decoder_position_bias,
layer_head_mask=layer_head_mask,
cross_attn_layer_head_mask=cross_attn_layer_head_mask,
past_key_value=past_key_value,
use_cache=use_cache,
output_attentions=output_attentions,
)
初始的时候这里的layer_module读取的是模型,past_key_values中存储的是6个None,到后面由于上一层的greedy_search中的参数不同,所以传入的past_key_values参数不同。
这里面的past_key_value保存的是6个对应的past_key_value内容(第一次全部为None),
past_key_value[0][0] = (1,8,1,64)
past_key_value[0][1] = (1,8,1,64)
past_key_value[0][2] = (1,8,11,64)
past_key_value[0][3] = (1,8,11,64)
............
............
past_key_value[5][0] = (1,8,1,64)
past_key_value[5][1] = (1,8,1,64)
past_key_value[5][2] = (1,8,11,64)
past_key_value[5][3] = (1,8,11,64)
上一次的t5stack留给这次的t5stack使用,都是同一层的在使用
注意,t5stack之中的past_value_state 第一次为 [None,None,None,None,None,None],后续每一次都是上一波的遗留下来的内容
也就是说,后面的t5block网络层中的内容传入的是同时期上一波t5block的输出,比如第二次调用t5block第二层的内容传入的是第一次调用t5block网络层第二层的内容。
t5block网络层中内容解读
进入t5block之中使用
hidden_states,present_key_value_state = self_attention_outputs[:2]
这里传递的是t5layerselfattention网络层之中传播的先前预测的内容(上一个网络结构同层的内容),这也能理解为什么这里刚开始
self_attn_past_key_value = past_key_value[:2]
......
......
self_attention_outputs = self.layer[0](
......
past_key_value=self_attn_past_key_value,
......
)
获得的
self_attn_past_key_value[0][0] = (1,8,1,64)
self_attn_past_key_value[0][1] = (1,8,1,64)
self_attn_past_key_value[0][2] = (1,8,11,64)
self_attn_past_key_value[0][3] = (1,8,11,64)
经过这一波数据输出之后,调用新的present_key_value_state
hidden_states,present_key_value_state = self_attention_outputs[:2]
这里的present_key_value_state的内容为
present_key_value_state[0] =
torch.Size([1, 8, 1, 64])
present_key_value_state[1] =
torch.Size([1, 8, 1, 64])
接下来经过decoder部分之后,调用新的present_key_value_state
cross_attention_outputs = self.layer[1](
hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
position_bias=encoder_decoder_position_bias,
layer_head_mask=cross_attn_layer_head_mask,
past_key_value=cross_attn_past_key_value,
query_length=query_length,
use_cache=use_cache,
output_attentions=output_attentions,
)
获得的新的present_key_value_state的内容
# Combine self attn and cross attn key value states
if present_key_value_state is not None:
present_key_value_state = present_key_value_state + cross_attention_outputs[1]
获得新的present_key_value_state的内容为
present_key_value_state =
torch.Size([1, 8, 1, 64])
torch.Size([1, 8, 1, 64])
torch.Size([1, 8, 11, 64])
torch.Size([1, 8, 11, 64])
另外两个位置的偏移参数也保存在后面
# Keep cross-attention outputs and relative position weights
attention_outputs = attention_outputs + cross_attention_outputs[2:]
获得的位置偏移的内容为
attention_outputs =
torch.Size([1, 8, 1, 1])
torch.Size([1, 8, 1, 11])
t5layerselfattention的解读
t5block之中有两种模式,一种是t5layerselfattention的解读,一种是t5layerselfattention+t5layercrossattention网络结构的解读,这里我们解读t5layerselfattention
这里注入的past_key_value的内容应该为
None或者
(1,8,1,64)
(1,8,1,64)
t5layerselfattention+t5layercrossattention中t5layerselfattention代码解读
t5block之中有两种模式,一种是t5layerselfattention的解读,一种是t5layerselfattention+t5layercrossattention网络结构的解读,这里我们解读t5layerselfattention+t5layercrossattention网络结构中t5layerselfattention的代码内容
t5layerselfattention直接进入t5attention的内容之中
t5attention的第一次运行
第一次运行的时候
batch_size = 1,seq_length = 11,key_length = 11
然后我们进入调用的过程
query_states = shape(self.q(hidden_states))
得到
query_states = (1,8,1,64)
(这里的query_states的内容其实是固定的)
接下来进入对于key_states和value_states的操作之中
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
进入project函数之中去查看内容
def project(hidden_states, proj_layer, key_value_states, past_key_value):
"""projects hidden states correctly to key/query states"""
if key_value_states is None:
# self-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(hidden_states))
elif past_key_value is None:
# cross-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(key_value_states))
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
else:
# cross-attn
hidden_states = past_key_value
return hidden_states
这里的key_value_states is None,后面的elif、if语句都没有被调用过,直接调用网络层
hidden_states = shape(proj_layer(hidden_states))
获得的结果
hidden_states = torch.size([1,8,11,64])
接下来调用
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
获得的结果
key_states = torch.Size([1, 8, 11, 64])
value_states = torch.Size([1, 8, 11, 64])
然后计算相应的分数
# compute scores
scores = torch.matmul(
query_states, key_states.transpose(3, 2)
) # equivalent of torch.einsum("bnqd,bnkd->bnqk", query_states, key_states), compatible with onnx op>9
获得结果
scores = (1,8,11,11)
接下来计算position_bias的内容
if position_bias is None:
if not self.has_relative_attention_bias:
position_bias = torch.zeros(
(1, self.n_heads, real_seq_length, key_length), device=scores.device, dtype=scores.dtype
)
if self.gradient_checkpointing and self.training:
position_bias.requires_grad = True
else:
position_bias = self.compute_bias(real_seq_length, key_length)
# if key and values are already calculated
# we want only the last query position bias
if past_key_value is not None:
position_bias = position_bias[:, :, -hidden_states.size(1) :, :]
if mask is not None:
position_bias = position_bias + mask # (batch_size, n_heads, seq_length, key_length)
这里应该运行的内容为
position_bias = self.compute_bias(real_seq_length,key_length)
得到position_bias的形状
position_bias = (1,8,11,11)
接下来的操作的内容
scores += position_bias
attn_weights = nn.functional.softmax(scores.float(), dim=-1).type_as(
scores
) # (batch_size, n_heads, seq_length, key_length)
attn_weights = nn.functional.dropout(
attn_weights, p=self.dropout, training=self.training
) # (batch_size, n_heads, seq_length, key_length)
# Mask heads if we want to
if layer_head_mask is not None:
attn_weights = attn_weights * layer_head_mask
这里的attn_weights = (1,8,11,11)
然后接下来经历一波输出
attn_output = unshape(torch.matmul(attn_weights,value_states))
attn_output = self.o(attn_output)
attn_weights,包括key_states、value_states以及position_bias都相当于中间过程的参数内容,只有outputs是最终结果的参数的内容
最后将这些内容保存成tulpe输出
present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else None
outputs = (attn_output,) + (present_key_value_state,) + (position_bias,)
if output_attentions:
outputs = outputs + (attn_weights,)
return outputs
这里计算出来的position_bias第一次为None,之后计算出来会往后传递,节约了模型的运行时间。position_bias在6个encoder中的selflayerattention部分是一样的,在6个decoder中的selflayerattention是一样的,6个decoder中的selfcrossattention中的内容是一样的,selflayerattention和selfcrossattention中的position_bias是不一样的
t5attention encoder 第二次调用
第一次调用完就结束了,在预测过程之中,encoder只调用一次6个对应的t5attention encoder内容,encoder调用完成之后,decoder部分的内容是不断地被调用,直到decoder部分输出预测的停止符号为止
t5layerselfattention+t5layercrossattention中t5layerselfattention代码解读
第一次调用的过程没有之前的t5layerselfattention的调用,decoder_input_ids = (1,1)
这里的decoder_input_ids是一开始就初始化好的输入的参数,与之前的encoder_outputs的内容无关
从t5forconditionalgeneration的类别来看
decoder_outputs = self.decoder(
input_ids=decoder_input_ids,
attention_mask=decoder_attention_mask,
inputs_embeds=decoder_inputs_embeds,
past_key_values=past_key_values,
encoder_hidden_states=hidden_states,
encoder_attention_mask=attention_mask,
head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
这里的之前encoder输出的部分只有
encoder_hidden_states=hidden_states
调用了之前的hidden_states = (1,11,512),其余的参数都与encoder部分无关
然后进入t5block的类别进行查看
self_attention_outputs = self.layer[0](
hidden_states,
attention_mask=attention_mask,
position_bias=position_bias,
layer_head_mask=layer_head_mask,
past_key_value=self_attn_past_key_value,
use_cache=use_cache,
output_attentions=output_attentions,
)
也就是说在decoder中的selflayerattention调用始终与之前encoder的输出无关
查看t5block中的decoder部分内容
cross_attention_outputs = self.layer[1](
hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
position_bias=encoder_decoder_position_bias,
layer_head_mask=cross_attn_layer_head_mask,
past_key_value=cross_attn_past_key_value,
query_length=query_length,
use_cache=use_cache,
output_attentions=output_attentions,
)
decoder中的crosslayerattention部分会调用之前encoder的输出
key_value_states = encoder_hidden_states
这里我们先查看第一次encoder部分的输出
第一次decoder部分的t5layerselfattention代码调用
刚开始的参数
batch_size,seq_length = hidden_states.shape[:2]
real_seq_length = seq_length
获得的参数
batch_size = 1,seq_length = 1,real_seq_length = 1
接下来这里调用网络层是不变的
query_states = shape(self.q(hidden_states))
获得query_states内容
query_states = torch.Size([1, 8, 1, 64])
然后调用
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
获得形状
key_states = torch.tensor([1, 8, 1, 64])
value_states = torch.tensor([1, 8, 1, 64])
后面的程序操作与上面操作类似,最后调用输出内容
outputs = (attn_output,)+(present_key_value_state,)+(position_bias,)
第二次decoder部分的t5layerselfattention代码调用(这里的第二次为调用了6个encoder的t5layerselfattention以及decoder中的6个encoder的t5layerselfattention和t5layercrossattention内容)
这里的第二次相当于预测完第一个数值之后,第二次运行到新的位置。这里调用的past_key_value[0]相当于上一个位置同一层输出的key_states,past_key_value[1]相当于上一个位置同一层输出的value_states(比如这里是第二波6个encoder+3个decoder+第4个decoder的selflayerattention,那么前面就相当于第一波的6个encoder+3个decoder+第4个decoder的selflayerattention的内容)
接下来进入
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
else:
# cross-attn
hidden_states = past_key_value
这里如果是t5layerselfattention的时候会调用第一个if,如果是crossattention的时候会调用第二个if
如果为t5layerselfattention的时候,在project函数里面会调用如下代码
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
............
return hidden_states
获得第二波中的输出内容
key_states.size = torch.Size([1, 8, 2, 64])
value_states.size = torch.Size([1, 8, 2, 64])
接下来调用scores内容
# compute scores
scores = torch.matmul(
query_states, key_states.transpose(3, 2)
) # equivalent of torch.einsum("bnqd,bnkd->bnqk", query_states, key_states), compatible with onnx op>9
获得的结果
scores = torch.Size([1, 8, 1, 2])
接下来查看position_bias的计算
if position_bias is None:
if not self.has_relative_attention_bias:
position_bias = torch.zeros(
(1, self.n_heads, real_seq_length, key_length), device=scores.device, dtype=scores.dtype
)
if self.gradient_checkpointing and self.training:
position_bias.requires_grad = True
else:
position_bias = self.compute_bias(real_seq_length, key_length)
这里得到的position_bias的结果
position_bias = torch.Size([1, 8, 2, 2])
接下来的操作,有对应的一行小字标注:
if key and values are already calculated,
we want only the last query position bias.
调用对应的代码
if past_key_value is not None:
position_bias = position_bias[:, :, -hidden_states.size(1) :, :]
注意取出来的是最后面的一维,取出来之后,position_bias = (1,8,1,2)
然后调用语句
scores += position_bias
#scores = (1,8,1,2)
attn_weights = nn.functional.softmax(scores.float(), dim=-1).type_as(
scores
) # (batch_size, n_heads, seq_length, key_length)
attn_weights = nn.functional.dropout(
attn_weights, p=self.dropout, training=self.training
) # (batch_size, n_heads, seq_length, key_length)
# Mask heads if we want to
if layer_head_mask is not None:
attn_weights = attn_weights * layer_head_mask
到这为止scores的内容都为(1,8,1,2)
接下来调用
attn_output = unshape((torch.matmul(attn_weights,value_states))
attn_weights = (1,8,1,2),value_states = (1,8,2,64)
相乘之后得到结果(1,8,1,64)
然后使用unshape之后进行输出
attn_output = unshape(torch.matmul(attn_weights,value_states))
#attn_output = (1,1,512)
attn_output = self.o(attn_output)
获得结果
attn_output = (1,1,512)
t5layerselfattention+t5layercrossattention中t5layercrossattention代码解读
t5block之中有两种模式,一种是t5layerselfattention的解读,一种是t5layerselfattention+t5layercrossattention网络结构的解读,这里我们解读t5layerselfattention+t5layercrossattention网络结构中t5layercrossattention的代码内容
第一次调用t5layercrossattention
前面的参数跟selflayerattention差不多
batch_size = 1,seq_length = 1,real_seq_length = 1
接着调用语句
key_length = real_seq_length if key_value_states is None else key_value_states.shape[1]
这里由于key_value_states不为None,所以这里获取得到的是
key_length = 11
这里的key_value_states = (1,11,512),就是之前6个encoder输出的内容的结果(6个t5layercrossattention的结果一样)
接下来调用project映射部分的内容
def project(hidden_states, proj_layer, key_value_states, past_key_value):
"""projects hidden states correctly to key/query states"""
if key_value_states is None:
# self-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(hidden_states))
elif past_key_value is None:
# cross-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(key_value_states))
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
else:
# cross-attn
hidden_states = past_key_value
return hidden_states
第一波layercrossattention直接调用上面的这一语句
elif past_key_value is None:
hidden_states = shape(proj_layer(key_value_states))
这里的key_value_states的内容为之前encoder输出的部分(1,8,11,64)
因此这里的hidden_states = (1,8,11,64)
然后past_key_value == None后面的if语句没有调用
接下来调用
query_states = shape(self.q(hidden_states))
query_states = (1,8,1,64)
然后后面两个调用
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
得到
key_states = (1,8,11,64)
value_states = (1,8,11,64)
然后scores调用中间过程
scores = torch.matmul(query_states,key_states.transpose(3,2))
得到结果
scores = (1,8,1,64)*(1,8,64,11) = (1,8,1,11)
接着调用后续的语句
scores += position_bias
attn_weights = nn.functional.softmax(scores.float(), dim=-1).type_as(
scores
) # (batch_size, n_heads, seq_length, key_length)
attn_weights = nn.functional.dropout(
attn_weights, p=self.dropout, training=self.training
) # (batch_size, n_heads, seq_length, key_length)
# Mask heads if we want to
if layer_head_mask is not None:
attn_weights = attn_weights * layer_head_mask
attn_weights = (1,8,1,11)
最后相乘并返回
attn_output = unshape(torch.matmul(attn_weights,value_states))
attn_output= self.o(attn_output)
获得结果
attn_output = (1,8,1,11)*(1,8,11,64) = (1,8,1,64)->(1,1,512)
attn_output经过线性层之后->(1,1,512)
最后把这些参数都打包在一起进行输出
present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else None
outputs = (attn_output,) + (present_key_value_state,) + (position_bias,)
if output_attentions:
outputs = outputs + (attn_weights,)
第二次调用t5layercrossattention内容
刚开始调用的参数一样
batch_size,seq_length = hidden_states.shape[:2]
real_seq_length = seq_length
这里的batch_size = 1,seq_length = 1,real_seq_length = 1
接着调用
key_length = real_seq_length if key_value_states is None else key_value_states.shape[1]
获得参数
key_length = 11
唯一的区别就在于key_states和value_states的调用过程不一样
key_states = project(
hidden_states, self.k, key_value_states, past_key_value[0] if past_key_value is not None else None
)
value_states = project(
hidden_states, self.v, key_value_states, past_key_value[1] if past_key_value is not None else None
)
首先,这里传入的past_key_value[0]和past_key_value[1]为同一层次上一波的运行的结果
这里调用的past_key_value[0]相当于上一个位置同一层输出的key_states,past_key_value[1]相当于上一个位置同一层输出的value_states(比如这里是第二波6个encoder+3个decoder+第4个decoder的selflayerattention,那么前面就相当于第一波的6个encoder+3个decoder+第4个decoder的selflayerattention的内容)
接下来进入project函数之中
def project(hidden_states, proj_layer, key_value_states, past_key_value):
"""projects hidden states correctly to key/query states"""
if key_value_states is None:
# self-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(hidden_states))
elif past_key_value is None:
# cross-attn
# (batch_size, n_heads, seq_length, dim_per_head)
hidden_states = shape(proj_layer(key_value_states))
if past_key_value is not None:
if key_value_states is None:
# self-attn
# (batch_size, n_heads, key_length, dim_per_head)
hidden_states = torch.cat([past_key_value, hidden_states], dim=2)
else:
# cross-attn
hidden_states = past_key_value
return hidden_states
直接运行最后一个else
hidden_states = past_key_value
获得hidden_states = torch.Size([1, 8, 11, 64])
总结一下project函数中的内容为,第一个if针对第一次的selflayerattention(包括encoder和decoder部分),else针对第一次的layercrossattention,第二个if针对第二次~第n次的selflayerattention,else针对第二次~第n次的layercrossattention
后续的操作都差不多
(1,8,1,64)*(1,8,64,11) = (1,8,1,11)
(1,8,1,11)*(1,8,11,64) = (1,8,1,64)