
Hadoop入门(十一)——集群崩溃的处理方法(图文详解步骤2021)
既然这章讲的是集群崩溃的处理方法,因此我们先把一个集群搞崩溃
接Hadoop入门(十),上回已经把集群配置好了,并测试可运行。
我们接下来将其搞崩溃
当然这次如果是重新打开虚拟机的话,需要重新启动集群
注意:这次就不需要初始化了
系列文章传送门
这个系列文章传送门:
Hadoop入门(一)——CentOS7下载+VM上安装(手动分区)图文步骤详解(2021)
Hadoop入门(二)——VMware虚拟网络设置+Windows10的IP地址配置+CentOS静态IP设置(图文详解步骤2021)
Hadoop入门(三)——XSHELL7远程访问工具+XFTP7文件传输(图文步骤详解2021)
Hadoop入门(四)——模板虚拟机环境准备(图文步骤详解2021)
Hadoop入门(五)——Hadoop集群搭建-克隆三台虚拟机(图文步骤详解2021)
Hadoop入门(六)——JDK安装(图文步骤详解2021)
Hadoop入门(七)——Hadoop安装(图文详解步骤2021)
Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)
Hadoop入门(九)——SSH免密登录 配置
Hadoop入门(十)——集群配置(图文详解步骤2021)
Hadoop入门(十一)——集群崩溃的处理方法(图文详解步骤2021)
Hadoop入门(十二)——配置历史服务器及日志的聚集(图文详解步骤2021)
Hadoop入门(十三)——集群常用知识(面试题)与技巧总结
Hadoop入门(十四)——集群时间同步(图文详解步骤2021)
Hadoop入门(十五)——集群常见错误及解决方案
文章目录
- Hadoop入门(十一)——集群崩溃的处理方法(图文详解步骤2021)
- 系列文章传送门
-
- 启动集群
- 搞崩集群的步骤(如果是已经被搞崩了跳过这里,直接看后面的解决办法)
- 正确的处理方法
-
- (1)先回到目录
- (2)先杀死进程
- (3)删除每一个集群上的data和logs
- (4)最后再进行格式化
- (5)初始化后再次启动集群
启动集群
回顾一下启动集群的操作
- 启动HDFS
[leokadia@hadoop102 hadoop-3.1.3]$sbin/start-dfs.sh - 在配置了 ResourceManager 的节点 (hadoop103 )启动 YARN
[leokadia@hadoop103 hadoop-3.1.3]$sbin/start-yarn.sh
接下来我们一通神操作将其搞崩溃
搞崩集群的步骤(如果是已经被搞崩了跳过这里,直接看后面的解决办法)
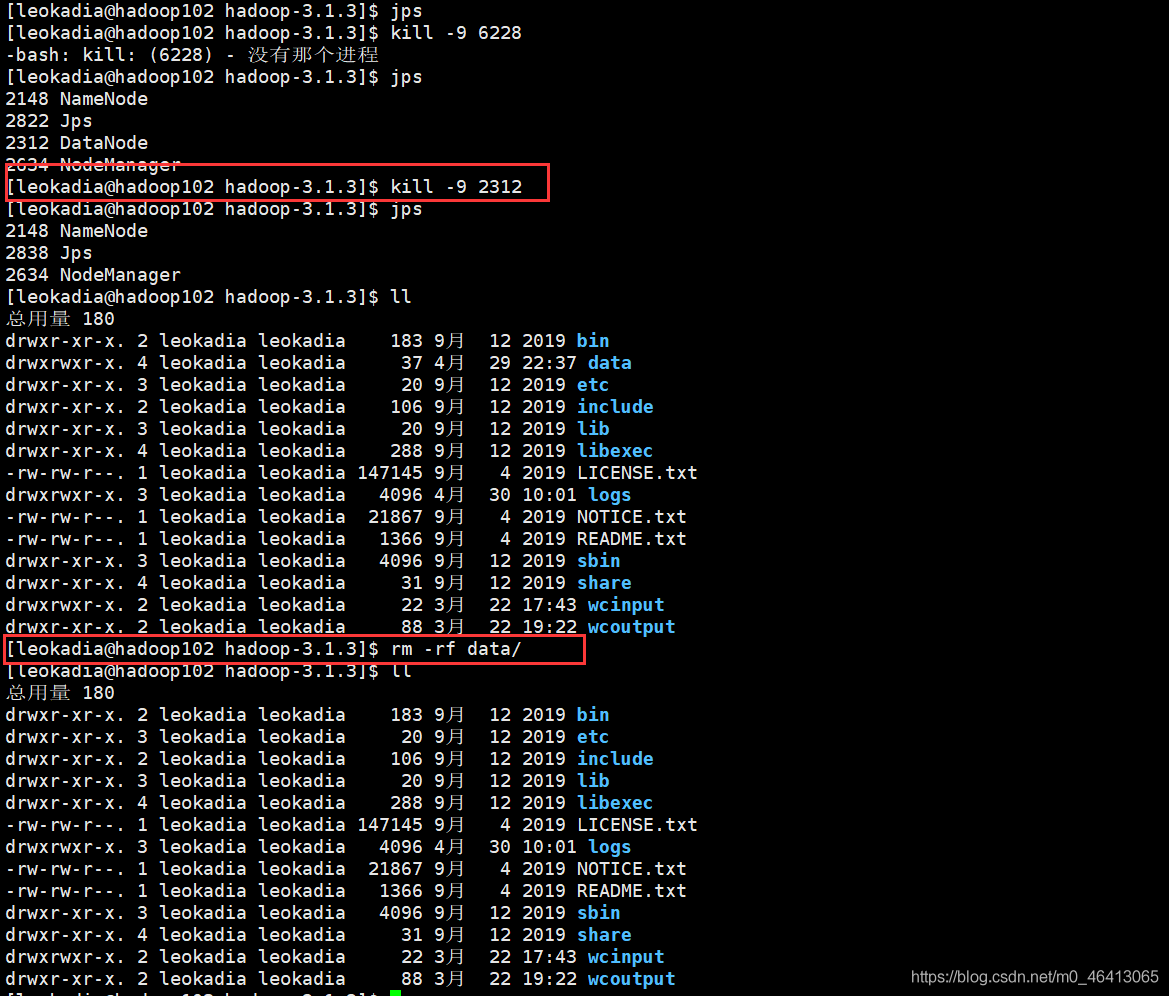
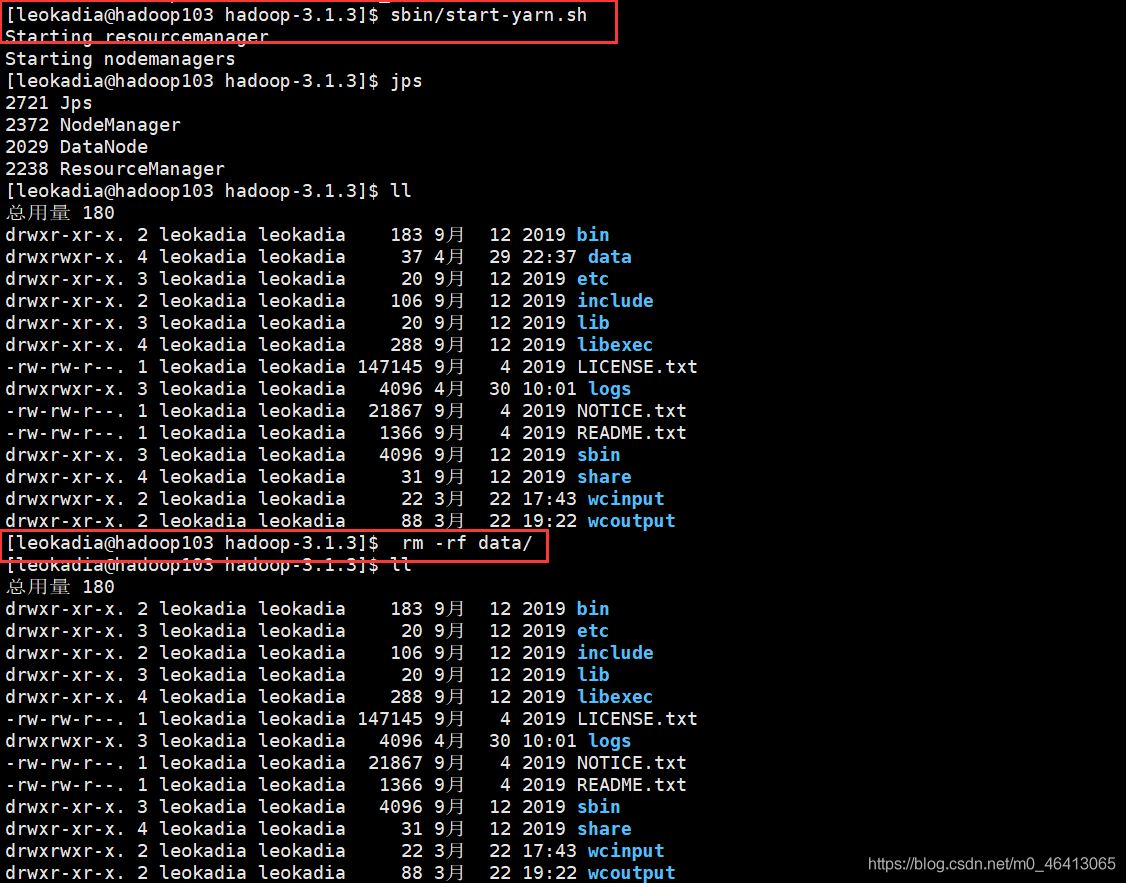
将102,103,104三份集群的数据都删掉
看数据能不能被下载
再点击页面的下载
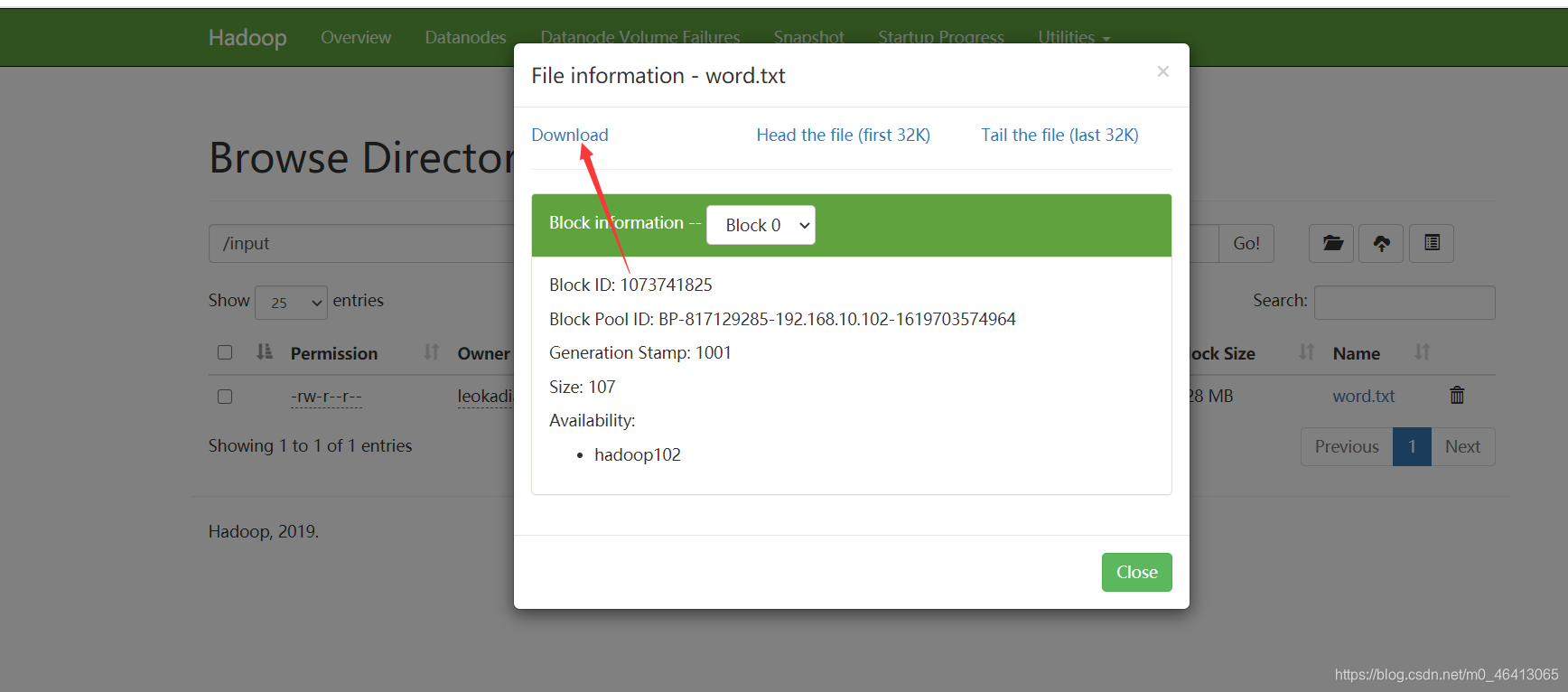
发现失败

想到的第一个解决办法是格式化
[leokadia@hadoop102 hadoop-3.1.3]$ hdfs namenode -format

但提示先停掉集群
[leokadia@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
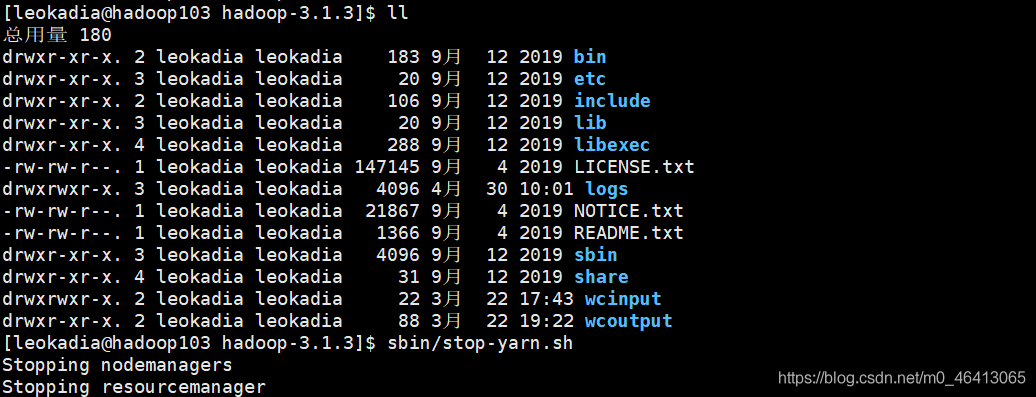
[leokadia@hadoop102 hadoop-3.1.3]$ sbin/stop-dfs.sh

发现集群已经ok了
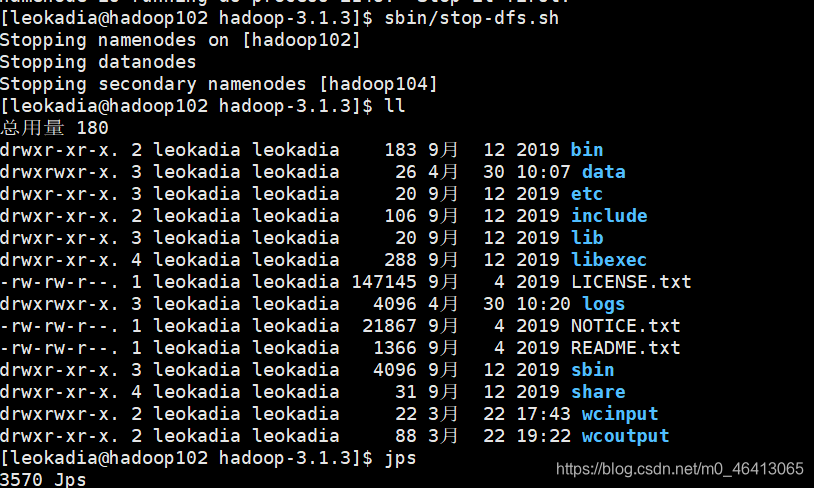
再试下能不能正常启动呢?
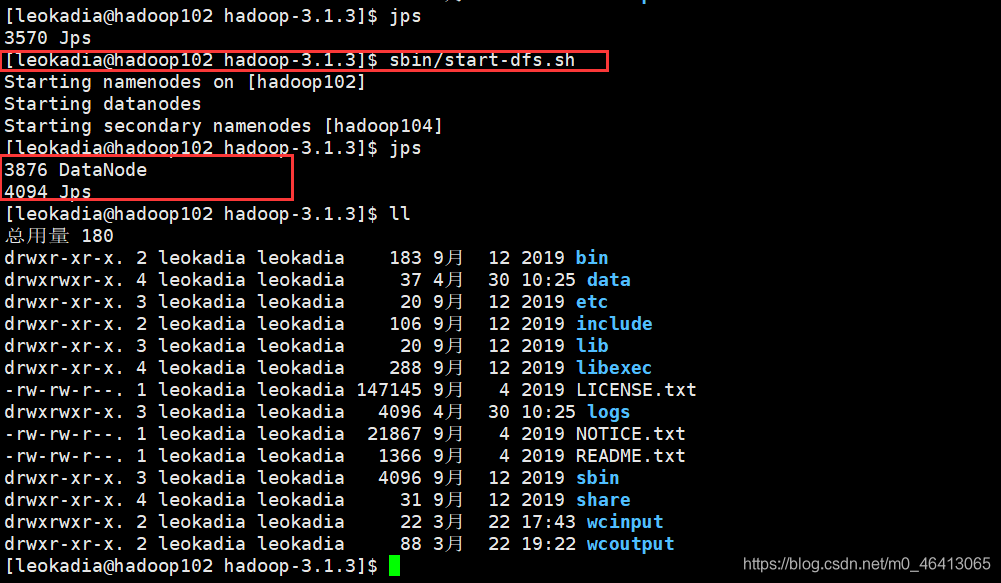
能正常启动,但是NameNode没了
查看目录,原来之前我们把DataNode中的name删了
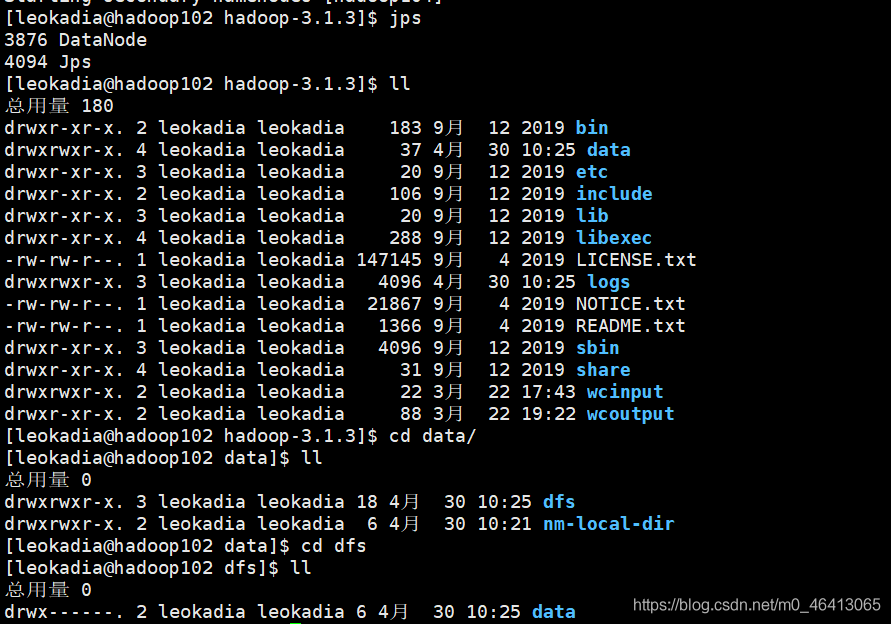
那怎么办?
格式化?
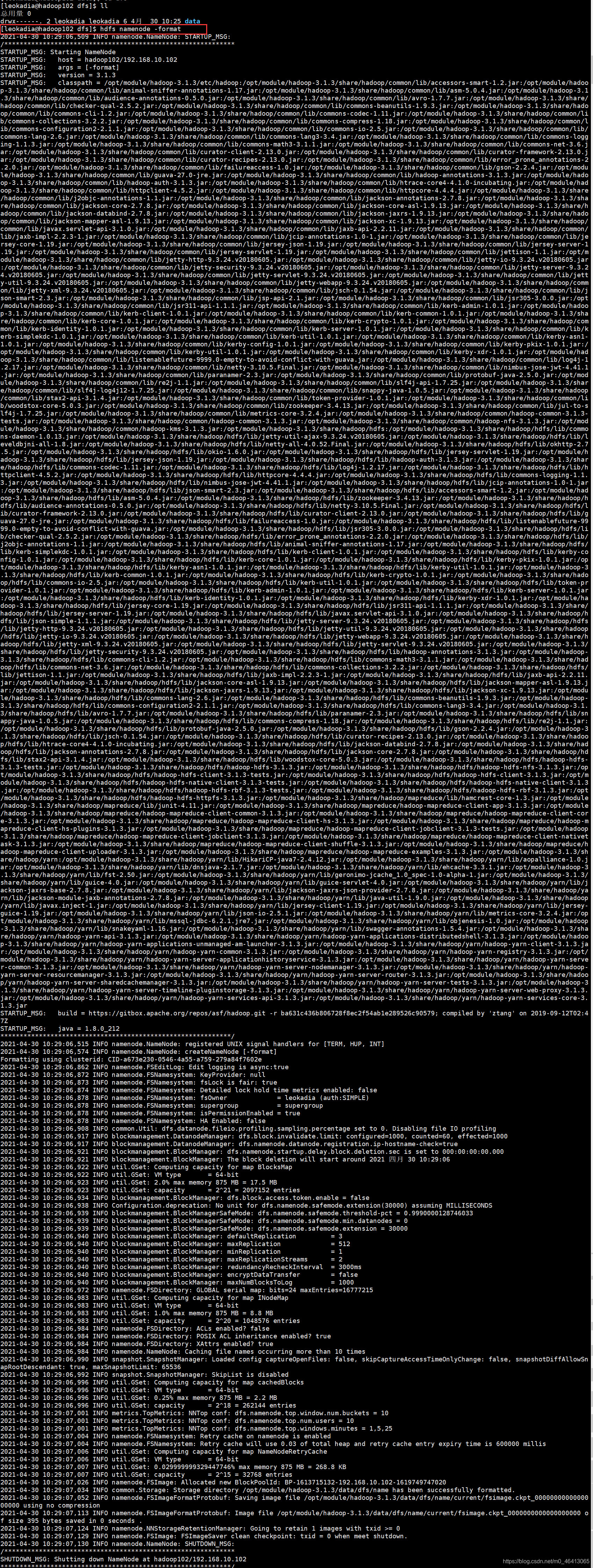
格式化成功
进入相应目录查看,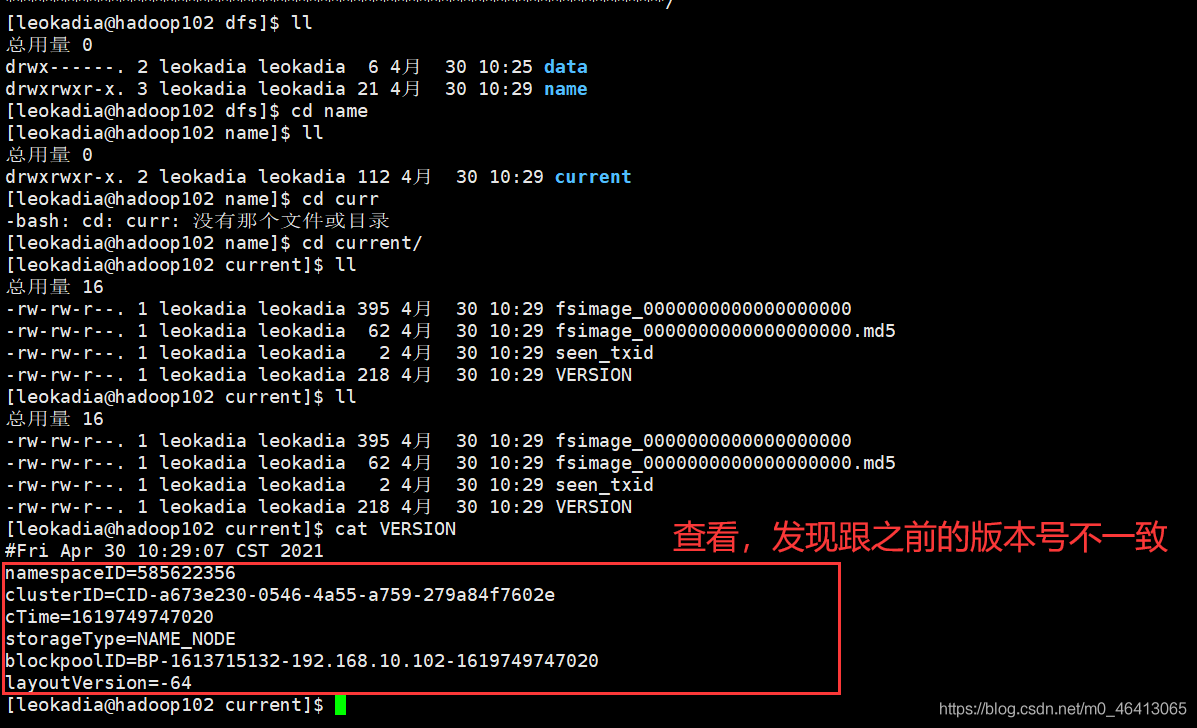
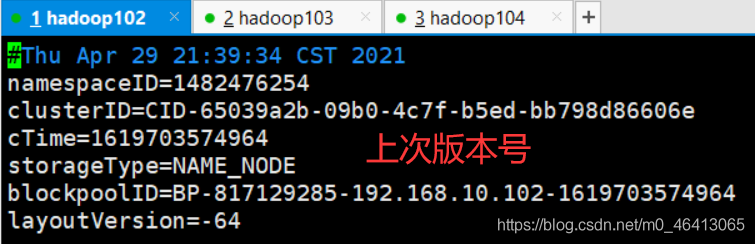
发现版本号跟上一个数据的不一样
此时进入HDFS网页
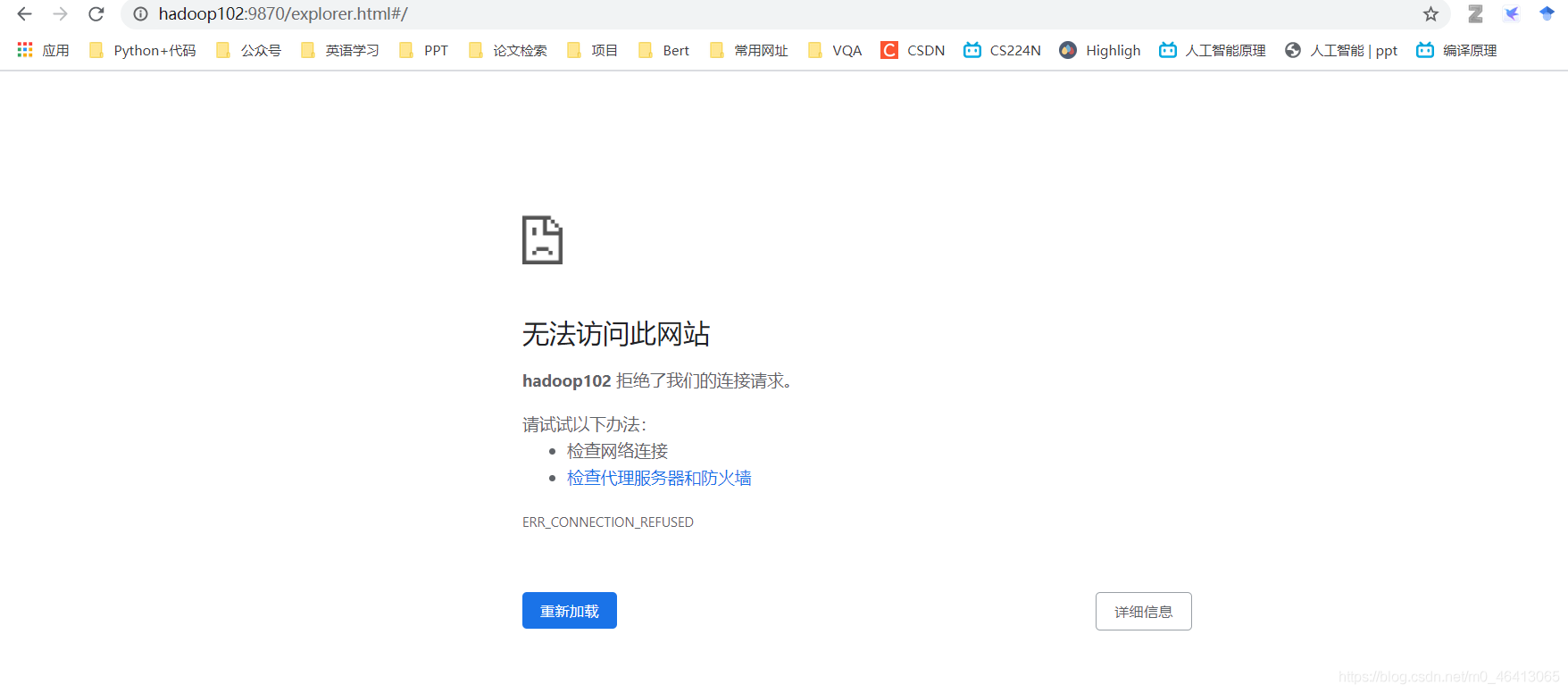
发现集群起不来了
查看一下什么情况
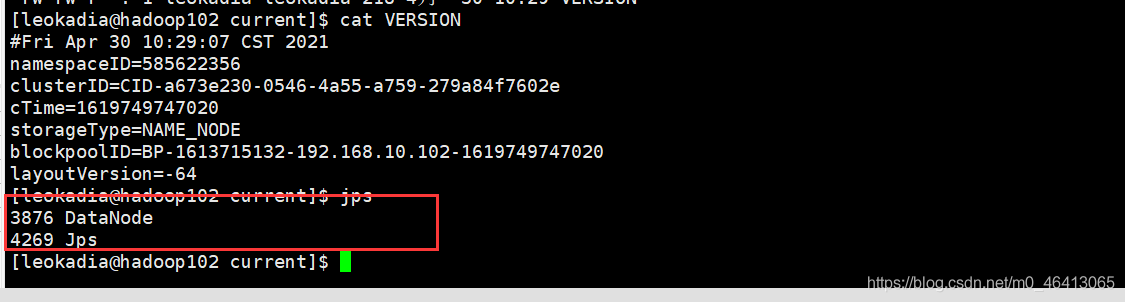


发现没有NameNode了,
此时开始慌了,集群崩溃了,进入正题!
正确的处理方法
(1)先回到目录
[leokadia@hadoop102 current]$ cd $HADOOP_HOME
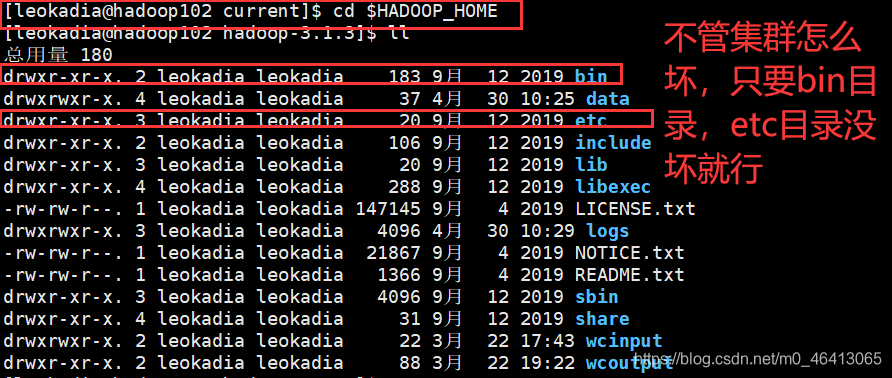
(2)先杀死进程
[leokadia@hadoop102 hadoop-3.1.3]$ sbin/stop-dfs.sh
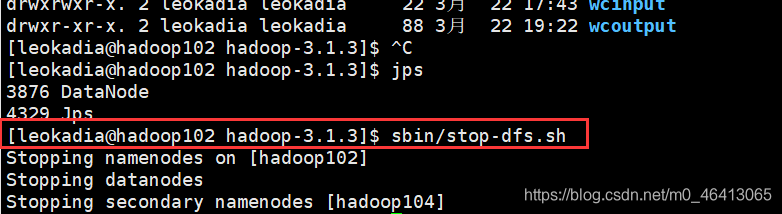
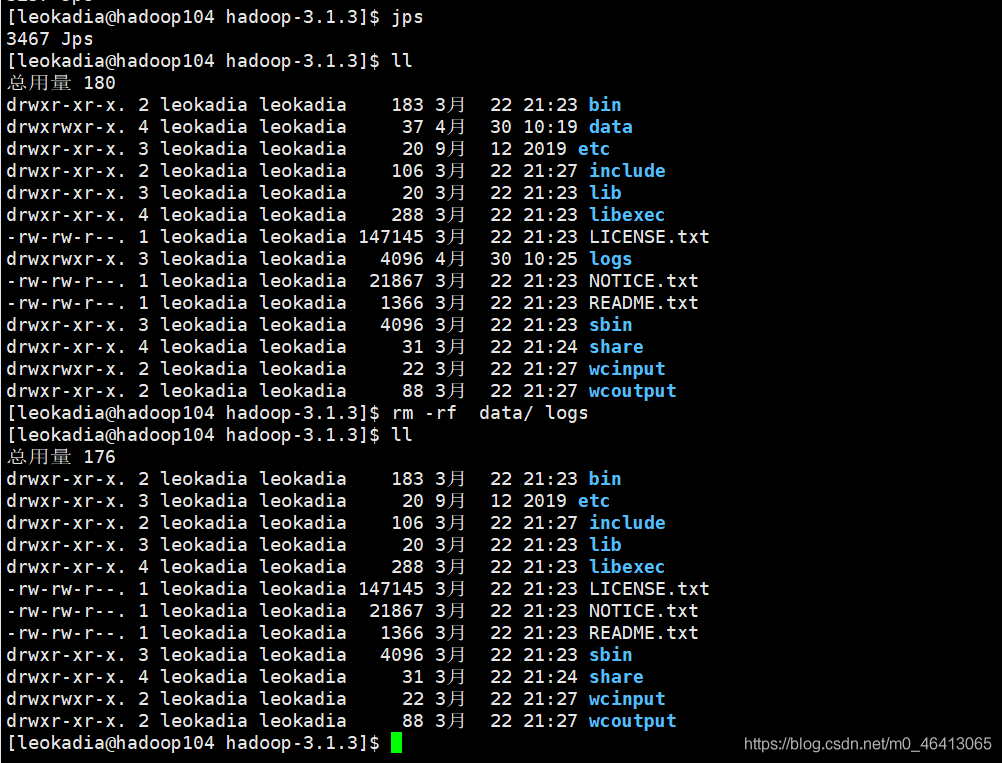
(3)删除每一个集群上的data和logs
[leokadia@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs
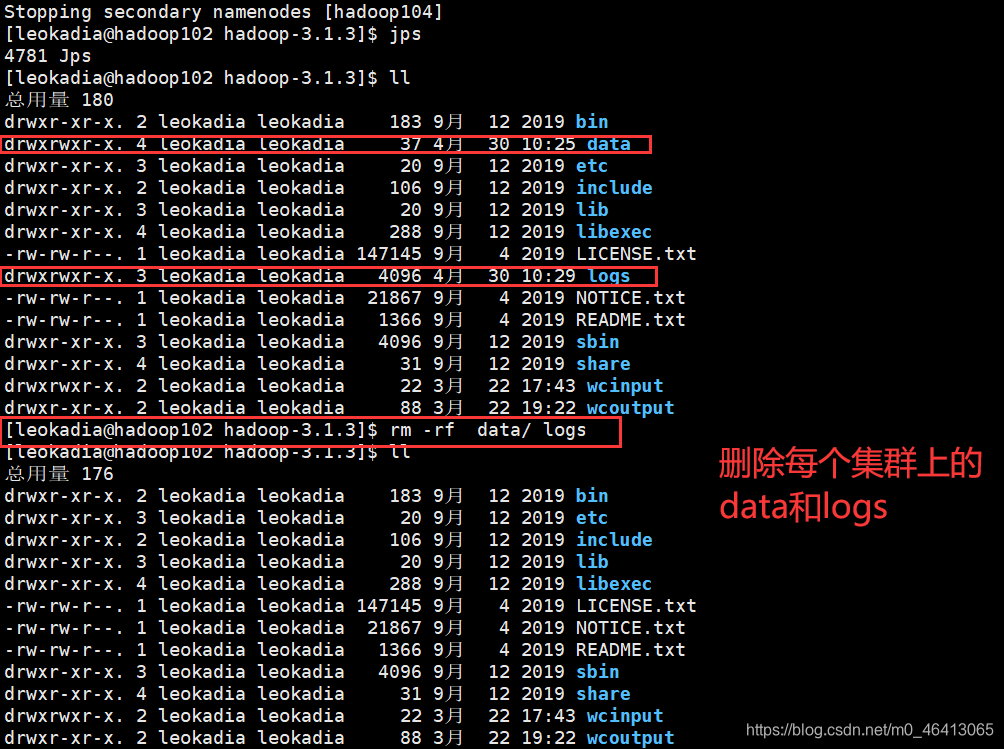
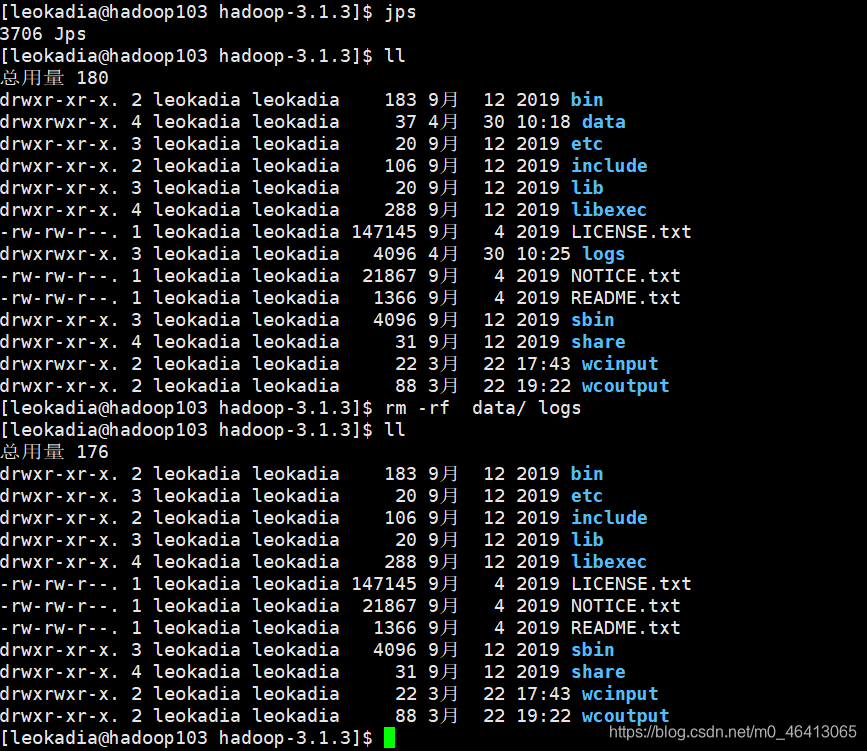
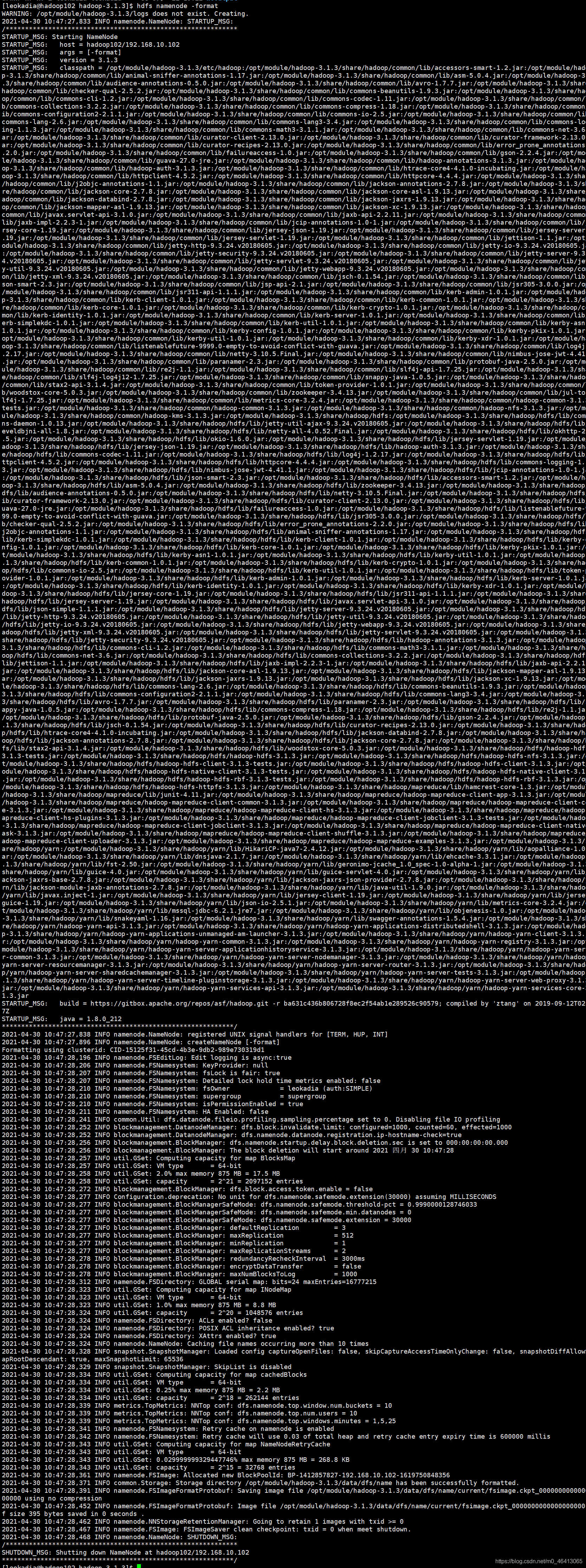
(4)最后再进行格式化
[leokadia@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
(5)初始化后再次启动集群
打扫干净屋子再启动
先停进程,再清历史数据,再格式化,最后启动
[leokadia@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
进入网页,可以看见网页可以出现了,但数据都被清空了
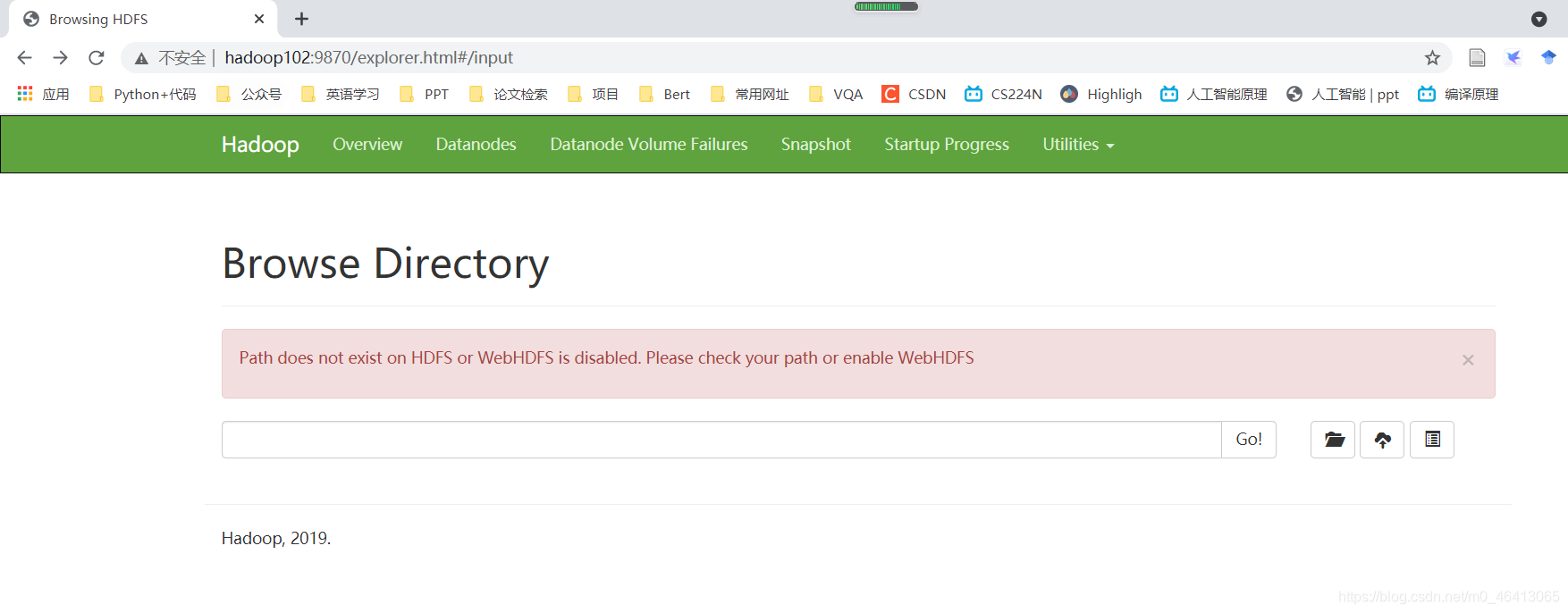
查看jps有NameNode了!

</article>