
面试题---容器
- 1.java容器有哪些?
- 2、数据容器主要分为了两类:
- 3、Iterator与Iterable
- 4、Collection 和 Collections 有什么区别?
- 5、List、Set、Map 之间的区别是什么?
- 6、HashMap 和 Hashtable 有什么区别?
- 7、如何决定使用hashMap还是TreeMap?
- 8、HashMap的实现原理?
- 9、什么是泛型?
- 自定义泛型接口、泛型类和泛型方法
- 简述泛型通配符<? extends T>和<? super T>
1.java容器有哪些?
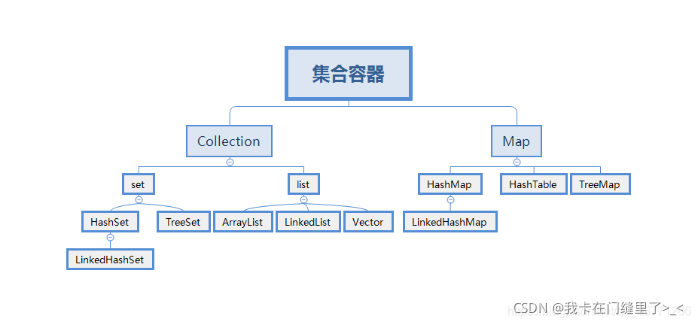
List,Map,Set ,Collection ,List ,LinkedList ,ArrayList ,Vector ,Stack ,Set Map ,Hashtable ,HashMap ,WeakHashMap
2、数据容器主要分为了两类:
- Collection: 存放独立元素的序列。
- Map:存放key-value型的元素对。(这对于需要利用key查找value的程序十分的重要!)
Collection定义了Collection类型数据的最基本、最共性的功能接口,而List对该接口进行了拓展。
-
LinkedList :==不保证线程安全,==其数据结构采用的是双向链表,此种结构的优势是删除和添加的效率很高,但随机访问元素时效率较ArrayList类低。实现了Deque接口,这个接口具有队列和栈的性质。内存利用率比较高。
-
ArrayList:==不保证线程安全,==其数据结构采用的是线性表,使用数组实现,集合扩容时会创建一个更大的数组,把原有数组复制到新数组中。此种结构的优势是访问和查询十分方便,但添加和删除的时候效率很低。 是容量可变的非线程安全列表,并且实现了RandomAcess标记接口,如果一个类实现了该接口,那么表示使用索引遍历比迭代器更快。
-
HashSet: Set类不允许其中存在重复的元素(集),无法添加一个重复的元素(Set中已经存在)。HashSet利用Hash函数进行了查询效率上的优化,其contain()方法经常被使用,以用于判断相关元素是否已经被添加过。
-
HashMap: 提供了key-value的键值对数据存储机制,可以十分方便的通过键值查找相应的元素,而且通过Hash散列机制,查找十分的方便。
3、Iterator与Iterable
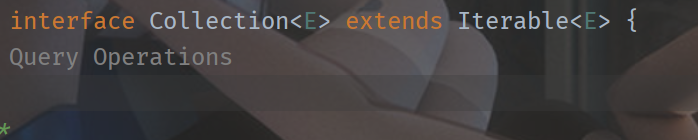
Collection中继承了接口Iterator
iterator为Java中的迭代器对象,是能够对List这样的集合进行迭代遍历的底层依赖。而iterable接口里定义了返回iterator的方法,相当于对iterator的封装,同时实现了iterable接口的类可以支持for each循环。
4、Collection 和 Collections 有什么区别?
Collection 是集合的接口,其继承类又List Set
Collections 是集合的工具类,定义了许多操作集合的静态方法。是帮助类
5、List、Set、Map 之间的区别是什么?
List:有序集合
Set:不重复集合,LinkedHashSet按照插入排序,SortedSet可排序,HashSet无序
Map:键值对集合
(1)元素的重复性:
- List集合中可以出现重复元素
- Set集合中不可以出现重复元素,在向Set集合中存储多个重复的元素时会出现覆盖
- Map集合采用key-value的形式存储,在Map中不能出现重复的Key键,但可以出现多个不同的Key对应相同的Value
(2)元素的有序性:
- List集合及其所有的实现类都确保了元素的有序性
- Set集合中的元素是无序的,但是某些Set集合通过特定的形式对其中的元素进行排序,如LinkedHashSet
- Map和Set一样对元素进行了无序存储,如:TreeMap根据Key键实现了元素的升序排序
(3)元素是否为空值:
- List集合中允许存在多个空值
- Set最多允许一个空值出现
- Map中只允许出现一个空键,但允许出现多个空值
6、HashMap 和 Hashtable 有什么区别?
- HashMap不是线程安全的 hashmap是一个接口 是map接口的子接口,是将键映射到值的对象,其中键和值都是对象,并且不能包含重复键,但可以包含重复值。HashMap允许null key和null value
- HashTable是线程安全的一个map。 HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,
主要区别:
在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。 HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。 HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。 Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。 最大的不同是,Hashtable的方法是Synchronized,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。 Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
7、如何决定使用hashMap还是TreeMap?
TreeMap<K,V> 的Key值是要求实现 java.lang.Comparable ,所以迭代的时候TreeMap默认是按照Key值升序排序的;
TreeMap的实现是基于红黑树结构。适用于按自然顺序或自定义顺序遍历键(key)。
HashMap<K,V> 的Key值实现散列 hashCode() ,分布是散列的、均匀的,不支持排序;数据结构主要是桶(数组),链表或红黑树。适用于在Map中插入、删除和定位元素。
8、HashMap的实现原理?
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
//HashMap的主干数组,可以看到就是一个Entry数组,初始值为空数组{},主干数组的长度一定是2的次幂,至于为什么这么做,后面会有详细分析。
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
Entry是hashMap中的一个静态内部类。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
hashMap的整体结构如下:
HashMap<String,Integer> s=new HashMap<>();
s.put("ss",1);//Entry对象,通过key算出一个数字,这个数字就是hash
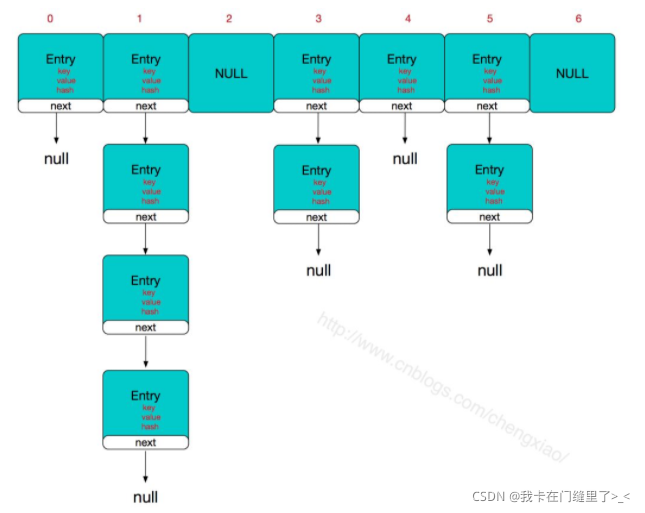
为什么会出现链表呢?
如果存储的对象,利用算法算出的hash值极有可能相同,这时候会出现一个next,这个next存储的实体对象
hashmap由数组+链表组成的,数组是主体,链表则是主要为了解决hash冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
initialCapacity默认为16,loadFactory默认为0.75
加载因子:
即默认情况下是16x0.75=12时,就会触发扩容操作。
在储存的时候,如果索引位置尚无元素,那么直接储存。如果有元素,那么就调用此key的equals方法与原有的元素的Key进行比较。如果返回true,说明在这个equals定义的规则上,这两个Key相同,那么将原有的key保留,用新的value代替原来的value。如果返回false,那么就说明这两个key在equals定义的规则下是不同元素,那么就与此链表的下一个结点进行比较,知道最后一个结点都没有相同元素,再下一个是null的时候,就用头插法将此key-value添加到链表上。
HashMap对重复元素的处理方法是:key不变,value覆盖。
当使用get方法获取key对应的value时,会和储存key-value时用同样的方法,得到key在数组中的索引值,如果此索引值上没有元素,就返回null。如果此索引值上有元素,那么就拿此key的equals方法与此位置元素上的key进行比较,如果返回true。就返回此位置元素对应的value。如果返回false,就一直按链表往下比较,如果都是返回false,那么就返回null。
另外:HashMap在JDK1.8之后引入红黑树结构。HashMap是线程不安全的,线程安全的是CurrentHashMap,不过此集合在多线程下效率低。
9、什么是泛型?
泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。
自定义泛型接口、泛型类和泛型方法
public class GenericTest {
public static void main(String[] args) {
Box<String> name = new Box<String>("corn");
Box<Integer> age = new Box<Integer>(712);
System.out.println("name class:" + name.getClass()); // com.qqyumidi.Box
System.out.println("age class:" + age.getClass()); // com.qqyumidi.Box
System.out.println(name.getClass() == age.getClass()); // true
}
}
class Box<T> {
private T data;
public Box() {
}
public Box(T data) {
this.data = data;
}
public T getData() {
return data;
}
}
由此,我们发现,在使用泛型类时,虽然传入了不同的泛型实参,但并没有真正意义上生成不同的类型,传入不同泛型实参的泛型类在内存上只有一个,即还是原来的最基本的类型(本实例中为Box),当然,在逻辑上我们可以理解成多个不同的泛型类型。
究其原因,在于Java中的泛型这一概念提出的目的,导致其只是作用于代码编译阶段,在编译过程中,对于正确检验泛型结果后,会将泛型的相关信息擦出,也就是说,成功编译过后的class文件中是不包含任何泛型信息的。泛型信息不会进入到运行时阶段。
对此总结成一句话:泛型类型在逻辑上看以看成是多个不同的类型,实际上都是相同的基本类型。