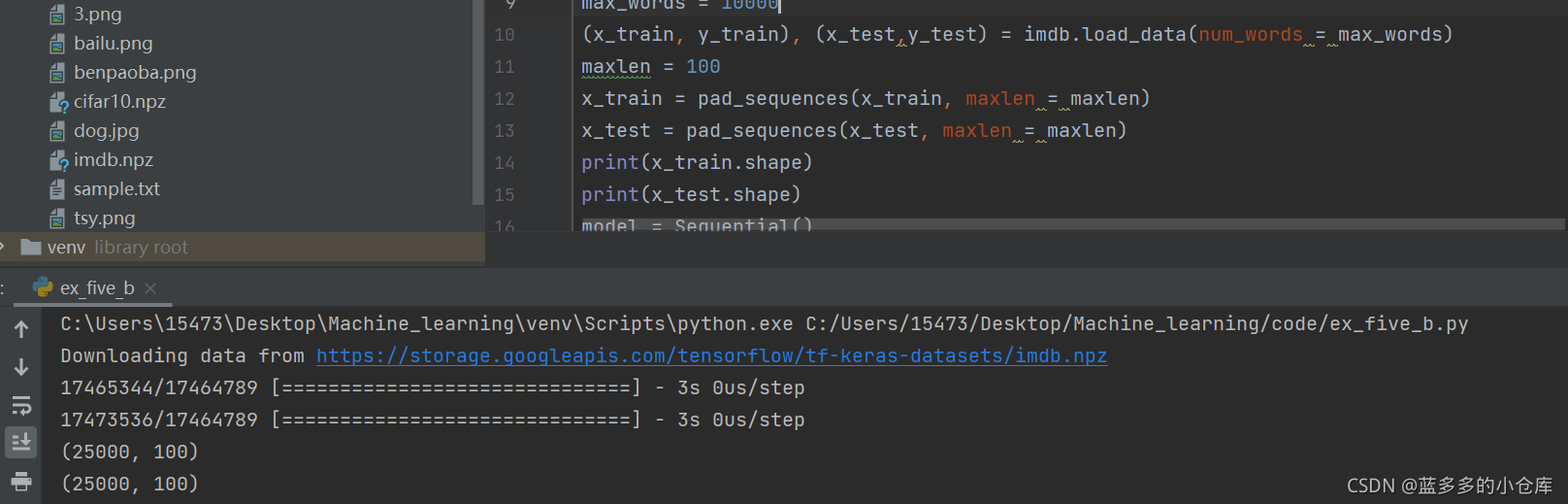
作为一名喜欢用../sources/文件夹来存放数据集的选手今天报了个错误:
报错部分代码:
(x_train, y_train), (x_test,y_test) = imdb.load_data(path = "../sources/imdb.npz", num_words = max_words)错误:
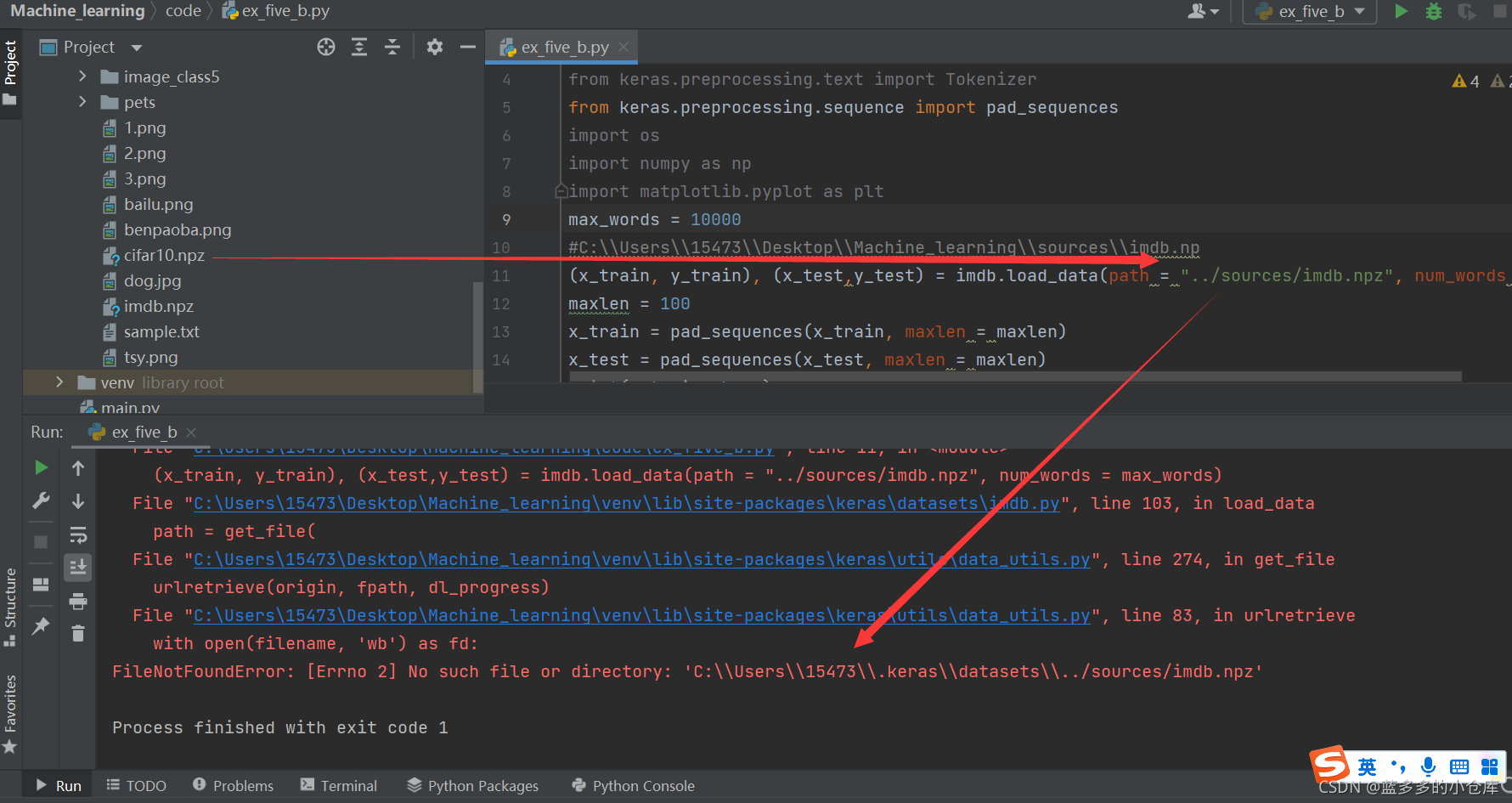 FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\15473\\.keras\\datasets\\../sources/imdb.npz'
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\15473\\.keras\\datasets\\../sources/imdb.npz'
原因:
/或\只能选一种,不能两个都用。既然\是他系统补全路径时候用的,那你只能选\,不能选/。所以要改成下面这个样子:
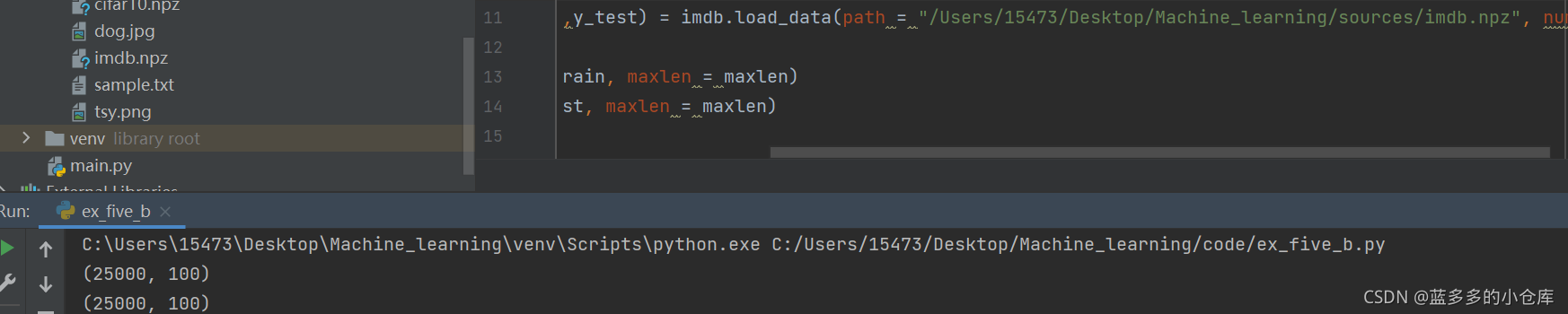
当然你直接写绝对路径也行:

官网参数的介绍如图:
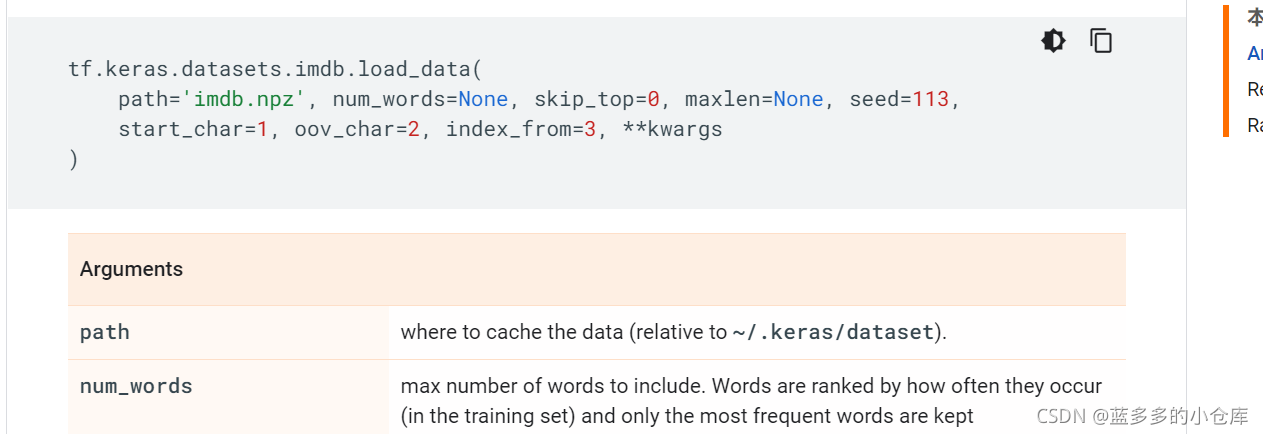
path: 如果你本地没有该数据集 (在 '~/.keras/datasets/' + path),它将被下载到此目录。在默认情况下,origin地址中的数据都会下载到~/.keras/datasets/filename这个文件夹,这个是path路径默认的指定路径。其中~是home主目录,windows下一般是C:\\Users\\用户名\\, keras前面的'.'表keras这个文件夹是隐藏文件夹,所以要查看这个文件夹的话需要设置文件夹的隐藏可见,然后再找。在ubuntu系统里,.keras/datasets文件夹是隐藏起来的,在主目录下按 ctrl+H,显示隐藏文件夹。./keras/datasets 就是代码中下载文件的默认存储文件夹。所以也可以将下载好的imdb.npz文件放在 .keras/datasets文件夹下。(我之前直接放桌面上了,所以路径好长,哈哈)
imdb.npz文件的下载地址:
https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
其实不用预先下载,之后加path指定路径这种麻烦的办法。不加path运行过程中直接就自动下载并使用了(当然有的人会因为下载速度很慢,长时间等待后失败。如果这样那我们就需要从上述链接先把文件预先下载到本地,下载后放在C:\Users\Administrator(这里是你的账户名)\.keras\datasets文件夹下,再加载即可。)
不加path代码运行时直接下载如图: