
WireShark
- 数据链路层
- 实作一熟悉 Ethernet 帧结构
- 实作二了解子网内/外通信时的 MAC 地址
- 实作三掌握 ARP 解析过程
- 网络层
- 实作一 熟悉 IP 包结构
- 实作二 IP 包的分段与重组
- 实作三 考察 TTL 事件
- 传输层
- 实作一 熟悉 TCP 和 UDP 段结构
- 实作二 分析 TCP 建立和释放连接
- 应用层
- 实作一 了解 DNS 解析
- 实作二 了解 HTTP 的请求和应答
数据链路层
实作一熟悉 Ethernet 帧结构
使用 Wireshark 任意进行抓包,熟悉 Ethernet 帧的结构,如:目的 MAC、源 MAC、类型、字段等。
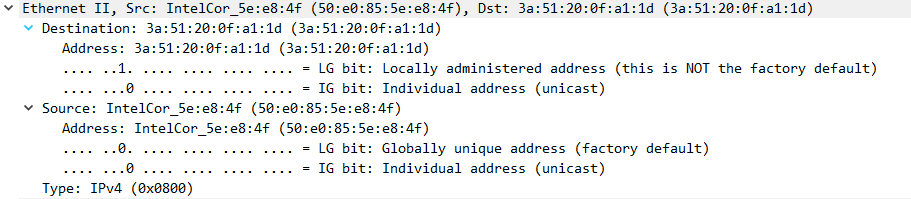 目的MAC:3a:51:20:0f:a1:1d
目的MAC:3a:51:20:0f:a1:1d
源MAC:50:e0:85:5e:e8:4f
类型:IPV4
字段:3a 51 20 0f a1 1d 50 e0 85 5e e8 4f 08 00
Q:你会发现 Wireshark 展现给我们的帧中没有校验字段,请了解一下原因。
A:通过查询资料,原来是因为有时校验和会由网卡计算,这时wireshark抓到的本机发送的数据包的校验和都是错误的,所以默认关闭了WireShark自己的校验,就不会出现校验字段。
实作二了解子网内/外通信时的 MAC 地址
- ping 你旁边的计算机(同一子网),同时用 Wireshark 抓这些包(可使用 icmp 关键字进行过滤以利于分析),记录一下发出帧的目的 MAC 地址以及返回帧的源 MAC 地址是多少?这个 MAC 地址是谁的?
- 然后 ping qige.io (或者本子网外的主机都可以),同时用 Wireshark 抓这些包(可 icmp 过滤),记录一下发出帧的目的 MAC 地址以及返回帧的源 MAC 地址是多少?这个 MAC 地址是谁的?
发出帧的目的MAC地址:2606:4700:3032::ac43:8f35
返回帧的源MAC地址:2606:4700:3032::ac43:8f35
这个MAC地址是请求访问的qige.io所在地址 - 再次 ping www.cqjtu.edu.cn (或者本子网外的主机都可以),同时用 Wireshark 抓这些包(可 icmp 过滤),记录一下发出帧的目的 MAC 地址以及返回帧的源 MAC 地址又是多少?这个 MAC 地址又是谁的?
发出帧的目的MAC地址:2001:da8:c801:99::102
返回帧的源MAC地址:2001:da8:c801:99::102
这是www.cqjtu.edu.cn所在
Q: 通过以上的实验,你会发现:
1.访问本子网的计算机时,目的 MAC 就是该主机的
2.访问非本子网的计算机时,目的 MAC 是网关的
请问原因是什么?
A:通过查询资料以及结合自身理解得知因为在对等网中MAC是该主机的,但是在不同网段就不是了,访问本子网的计算机时,不需要出该主机的地址,而访问非本子网的计算机时,网络需要先通过学校网络的网关才能出去,目的MAC就是网关的。
实作三掌握 ARP 解析过程
- 为防止干扰,先使用 arp -d * 命令清空 arp 缓存
- ping 你旁边的计算机(同一子网),同时用 Wireshark 抓这些包(可 arp 过滤),查看 ARP 请求的格式以及请求的内容,注意观察该请求的目的 MAC 地址是什么。再查看一下该请求的回应,注意观察该回应的源 MAC 和目的 MAC 地址是什么。
- 再次使用 arp -d * 命令清空 arp 缓存
- 然后 ping qige.io (或者本子网外的主机都可以),同时用 Wireshark 抓这些包(可 arp 过滤)。查看这次 ARP 请求的是什么,注意观察该请求是谁在回应。

Q:通过以上的实验,你应该会发现,
1.ARP 请求都是使用广播方式发送的
2.如果访问的是本子网的 IP,那么 ARP 解析将直接得到该 IP 对应的 MAC;如果访问的非本子网的 IP, 那么 ARP 解析将得到网关的 MAC。
请问为什么?
A: ARP 不能跨子网(子网 subnet 通过子网掩码 subnet mask 定义),同子网通信无需网关的参与,只要通过 ARP (地址解析协议)获取到对方的 MAC 地址就ok;
网络层
实作一 熟悉 IP 包结构
使用 Wireshark 任意进行抓包(可用 ip 过滤),熟悉 IP 包的结构,如:版本、头部长度、总长度、TTL、协议类型等字段。
版本(version):4
头部长度(Header Length):20 bytes
总长度(Total Length):40
TTL:128
协议类型:TCP(6)
Q:为提高效率,我们应该让 IP 的头部尽可能的精简。但在如此珍贵的 IP 头部你会发现既有头部长度字段,也有总长度字段。请问为什么?
A:表示报头长度的字段占头部的4bits,表示总长度的占16bits.每个IP数据报包含一个头部和一个正文部分。头部有一个20字节的定长部分和一个可选的变长部分。头部的IHL域指明了该头部有多长(以32位字的长度为位)。IHL最小值为5,表明头部没有可选项。此4位域的最大值为15,这限制了头部的最大长度为60字节。总长度域包含了该数据报中的所有内容,即头和数据。
实作二 IP 包的分段与重组
根据规定,一个 IP 包最大可以有 64K 字节。但由于 Ethernet 帧的限制,当 IP 包的数据超过 1500 字节时就会被发送方的数据链路层分段,然后在接收方的网络层重组。
缺省的,ping 命令只会向对方发送 32 个字节的数据。我们可以使用 ping 202.202.240.16 -l 2000 命令指定要发送的数据长度。此时使用 Wireshark 抓包(用 ip.addr == 202.202.240.16 进行过滤),了解 IP 包如何进行分段,如:分段标志、偏移量以及每个包的大小等。


由上面两图中可以看出,第一个IP包总长度为1500,偏移为0,第二个IP包总长度为548,偏移为1480,意思是两个IP包以第1480字节作为分隔的节点。
Q:分段与重组是一个耗费资源的操作,特别是当分段由传送路径上的节点即路由器来完成的时候,所以 IPv6 已经不允许分段了。那么 IPv6 中,如果路由器遇到了一个大数据包该怎么办?
A:1.IPV6源节点使用分段包头来发送大于去往目的节点的路径MTU的包。
⒉.前面的包头中“下一个包头”字段中的值为44,表示下一个包头为分片包头。要发送大于去往目的节点的路径MTU的包,源节点
可以将包分成若干分片,每个分片单独发送,并且在接收者处进行重组。
3.最初的,未分片的大数据包称为“原包”。不可分片部分包括IPV6包头以及那些必须由路由中的节点处理的扩展包头。
4.重组应遵循如下原则:原包只能由具有相同源地址、目的地址和分片标识的分片包重纽。重组后的包中的不可分片部分由第一个分
片包,也就是分片偏移量为0的那个包中分段包头前面所有的包头(不含分段包头)组成。
实作三 考察 TTL 事件
在 IP 包头中有一个 TTL 字段用来限定该包可以在 Internet上传输多少跳(hops),一般该值设置为 64、128等。
在验证性实验部分我们使用了 tracert 命令进行路由追踪。其原理是主动设置 IP 包的 TTL 值,从 1 开始逐渐增加,直至到达最终目的主机。
请使用 tracert www.baidu.com 命令进行追踪,此时使用 Wireshark 抓包(用 icmp 过滤),分析每个发送包的 TTL 是如何进行改变的,从而理解路由追踪原理。
 第一跳,其中Time To Live:1
第一跳,其中Time To Live:1
 第八跳,其中Time To Live:248
第八跳,其中Time To Live:248
TTL字段指定IP包被路由器丢弃之前允许通过的最大网段数量,Tracert 先发送 TTL 为 1 的回应数据包,并随后的每次发送过程将 TTL 递增 1,直到目标响应或 TTL 达到最大值,从而确定路由。
Q:在 IPv4 中,TTL 虽然定义为生命期即 Time To Live,但现实中我们都以跳数/节点数进行设置。如果你收到一个包,其 TTL 的值为 50,那么可以推断这个包从源点到你之间有多少跳?
A:至少有50跳
传输层
实作一 熟悉 TCP 和 UDP 段结构
-
用 Wireshark 任意抓包(可用 tcp 过滤),熟悉 TCP 段的结构,如:源端口、目的端口、序列号、确认号、各种标志位等字段。
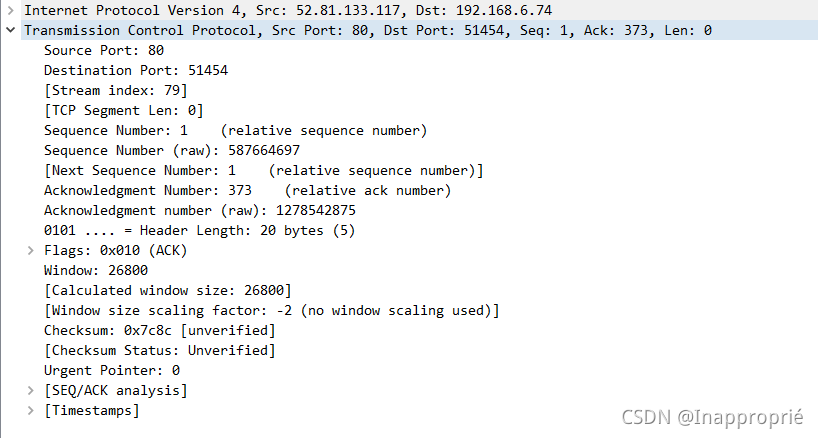
-
用 Wireshark 任意抓包(可用 udp 过滤),熟悉 UDP 段的结构,如:源端口、目的端口、长度等。

Q:由上大家可以看到 UDP 的头部比 TCP 简单得多,但两者都有源和目的端口号。请问源和目的端口号用来干什么?
A:各占2个字节,端口是传输层和应用层的服务接口,用于寻找发送端和接收端的进程,通过这两个端口号和IP头部的ip发送和接收号,可以唯一的确定一个连接。一般来讲,通过端口号和IP地址,可以唯一确定一个TCP连接,在网络编程中,通常被称为一个socket接口。UDP同TCP。
实作二 分析 TCP 建立和释放连接
-
打开浏览器访问 qige.io 网站,用 Wireshark 抓包(可用 tcp 过滤后再使用加上 Follow TCP Stream),不要立即停止 Wireshark 捕获,待页面显示完毕后再多等一段时间使得能够捕获释放连接的包。
-
请在你捕获的包中找到三次握手建立连接的包,并说明为何它们是用于建立连接的,有什么特征。
 这三行记录是三次握手,第一次由本机向目标发出,[SYN]标志位为1,第二次由目标向本机回复,[SYN][ACK]标志位都为1,第三次再由本机发出[ACK]为1 。
这三行记录是三次握手,第一次由本机向目标发出,[SYN]标志位为1,第二次由目标向本机回复,[SYN][ACK]标志位都为1,第三次再由本机发出[ACK]为1 。 -
请在你捕获的包中找到四次挥手释放连接的包,并说明为何它们是用于释放连接的,有什么特征。
 首先本机发出[FIN,ACK]为1的结束请求,对方收到后回复[FIN,ACK]也为1,本机再次回复[ACK]为1确定释放连接。
首先本机发出[FIN,ACK]为1的结束请求,对方收到后回复[FIN,ACK]也为1,本机再次回复[ACK]为1确定释放连接。
Q:去掉 Follow TCP Stream,即不跟踪一个 TCP 流,你可能会看到访问 qige.io 时我们建立的连接有多个。请思考为什么会有多个连接?作用是什么?
A:它们之间的连接是属于短连接,一旦数据发送完成后,就会断开连接。虽然,断开连接,但是页面还是存在,由于页面已经被缓存下来。一旦需要重新进行发送数据,就要再次进行连接。这样的连接,是为了实现多个用户进行访问。
Q:我们上面提到了释放连接需要四次挥手,有时你可能会抓到只有三次挥手。原因是什么?
A:可能把中间两次挥手合并为了一次。
应用层
实作一 了解 DNS 解析
1.先使用 ipconfig /flushdns 命令清除缓存,再使用 nslookup qige.io 命令进行解析,同时用 Wireshark 任意抓包(可用 dns 过滤)。
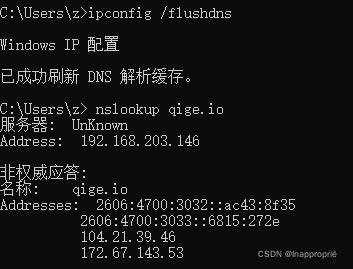

2.你应该可以看到当前计算机使用 UDP,向默认的 DNS 服务器的 53 号端口发出了查询请求,而 DNS 服务器的 53 号端口返回了结果。

3.可了解一下 DNS 查询和应答的相关字段的含义

1.QR:查询/应答标志。0表示这是一个查询报文,1表示这是一个应答报文
2.opcode,定义查询和应答的类型。0表示标准查询,1表示反向查询(由IP地址获得主机域名),2表示请求服务器状态
3.AA,授权应答标志,仅由应答报文使用。1表示域名服务器是授权服务器
4.TC,截断标志,仅当DNS报文使用UDP服务时使用。因为UDP数据报有长度限制,所以过长的DNS报文将被截断。1表示DNS报文超过512字节,并被截断
5.RD,递归查询标志。1表示执行递归查询,即如果目标DNS服务器无法解析某个主机名,则它将向其他DNS服务器继续查询,如此递归,直到获得结果并把该结果返回给客户端。0表示执行迭代查询,即如果目标DNS服务器无法解析某个主机名,则它将自己知道的其他DNS服务器的IP地址返回给客户端,以供客户端参考
6.RA,允许递归标志。仅由应答报文使用,1表示DNS服务器支持递归查询
7.zero,这3位未用,必须设置为0
8.rcode,4位返回码,表示应答的状态。常用值有0(无错误)和3(域名不存在)
Q:你可能会发现对同一个站点,我们发出的 DNS 解析请求不止一个,思考一下是什么原因?
A:将负载均衡的工作交给DNS,省去了网站管理维护负载均衡服务器的麻烦。
对于部署在服务器上的应用来说不需要进行任何的代码修改即可实现不同机器上的应用访问。
实作二 了解 HTTP 的请求和应答
1.打开浏览器访问 cqjtu.edu.cn 网站,用 Wireshark 抓包(可用http 过滤再加上 Follow TCP Stream),不要立即停止 Wireshark 捕获,待页面显示完毕后再多等一段时间以将释放连接的包捕获。
2.请在你捕获的包中找到 HTTP 请求包,查看请求使用的什么命令,如:GET, POST。并仔细了解请求的头部有哪些字段及其意义。

3.请在你捕获的包中找到 HTTP 应答包,查看应答的代码是什么,如:200, 304, 404 等。并仔细了解应答的头部有哪些字段及其意义。
 200(成功)
200(成功)
服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。如果是对您的 robots.txt 文件显示此状态码,则表示 Googlebot 已成功检索到该文件。
304(未修改)
自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。
如果网页自请求者上次请求后再也没有更改过,您应将服务器配置为返回此响应(称为 If-Modified-Since HTTP 标头)。服务器可以告诉 Googlebot 自从上次抓取后网页没有变更,进而节省带宽和开销。
404(未找到)
服务器找不到请求的网页。
Q:刷新一次 网站的页面同时进行抓包,你会发现不少的 304 代码的应答,这是所请求的对象没有更改的意思,让浏览器使用本地缓存的内容即可。那么服务器为什么会回答 304 应答而不是常见的 200 应答?
A:客户端在请求一份文件的时候,服务端会检查客户端是否存在该文件,如果客户端不存在该文件,则下载该文件并返回200;如果客户端存在该文件并且该文件在规定期限内没有被修改,则服务端只返回一个304,并不返回资源内容,客户端将会使用之前的缓存文件。