
Java 反序列化漏洞 学习笔记
- 前言
- 什么是 Java 序列化 / 反序列化
- 实现反序列化需要满足的条件
- Serializable
- Externalizable
- 关于writeObject() 与 readObject()
- java.io.ObjectOutputStream和writeObject()
- java.io.ObjectInputStream和readObject()
- 完整的 Java 序列化 / 反序列化流程
- 序列化过程
- 反序列化过程
- 总结
- Java 反序列化漏洞
- Java 序列化数据分析和objectAnnotation
- 总结
前言
Java的反序列化漏洞我感觉应该是比较常见而且危害较大的漏洞,而Java 反序列化技术大量应用于 JRMI( Java远程方法调用 ) , JMX( Java管理扩展 ) , JMS( Java消息服务 ) 中,因此 Java RMI 服务也算是 Java 反序列化漏洞的高发地 ,而前面也学过了Java RMI相关的知识,今天就来学一下Java 反序列化漏洞相关原理
什么是 Java 序列化 / 反序列化
Java 序列化就是把一个 Java Object 变成一个二进制字节数组 , 即 byte[] .
Java 反序列化就是把一个二进制字节数组(byte[]) 变回 Java 对象 , 即 Java Object .
Java 序列化/反序列化的目的无非就是用于 " 数据存储 " 或 " 数据传输 " .
实现反序列化需要满足的条件
Serializable
如果一个类要实现序列化操作 , 则必须实现 Serializable 接口
Serializable是一个空接口,接口中没有方法和属性字段 , 仅用于标识序列化的语义 , 代表该类可以进行序列化/反序列化操作 .
在序列化或反序列化过程中需要进行特殊处理的类要实现下面三个方法:
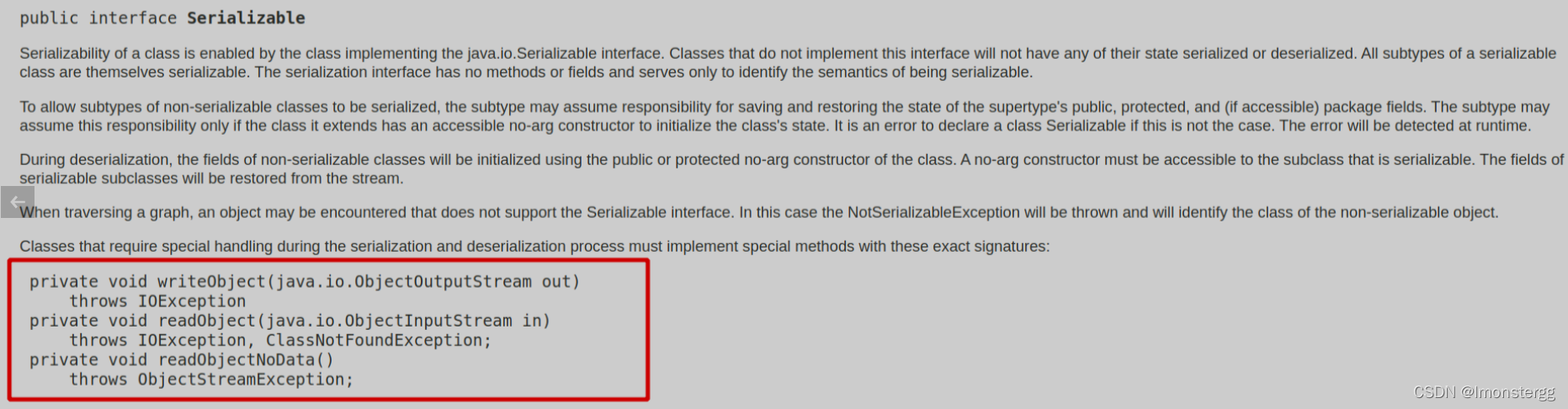
这里在额外说一下serialVersionUID 属性,每个可序列化的类在序列化时都会关联一个版本号 , 这个版本号就是 serialVersionUID 属性
在反序列化过程中会根据这个版本号来判断序列化对象的发送者和接收着是否有与该序列化/反序列化过程兼容的类 .( 简单的说就是序列化过程和反序列化过程都需要被序列化的类 , 通过 serialVersionUID 属性来判断这两个类的版本是否相同 , 是否是同一个类 ) . 如果不相同 , 则会抛出 InvalidClassException 异常
serialVersionUID 属性必须通过 static final long 修饰符来修饰 .
如果可序列化的类未声明 serialVersionUID 属性 , 则 Java 序列化时会根据类的各种信息来计算默认的 serialVersionUID 值 . 但是 Oracle 官方文档强烈建议所有可序列化的类都显示声明 serialVersionUID 值 .
Externalizable
不仅可以通过继承 Serializable 接口来标识某个类是可序列化的,事实上 , 还可以通过Externalizable 接口,该继承了 Serializable 接口
public interface Externalizable extends java.io.Serializable
通过 Externalizable 接口实现序列化和反序列化操作会相对麻烦一点 , 因为我们需要手动编写 writeExternal()方法和readExternal()方法 , 这两个方法将取代定制好的 writeObject()方法和 readObject()方法 .
那什么时候会使用 Externalizable 接口呢 ?
当我们仅需要序列化类中的某个属性 , 此时就可以通过 Externalizable 接口中的 writeExternal() 方法来指定想要序列化的属性 . 同理 , 如果想让某个属性被反序列化 , 通过 readExternal() 方法来指定该属性就可以了.
此外 , Externalizable 序列化/反序列化还有一些其他特性 , 比如 readExternal() 方法在反序列化时会调用默认构造函数 , 实现 Externalizable 接口的类必须要提供一个 Public 修饰的无参构造函数等等
在 Externalizable 与 Serializable 一文中 , 简单的总结了 Serializable 和 Externalizable 两个接口的区别及优劣 .
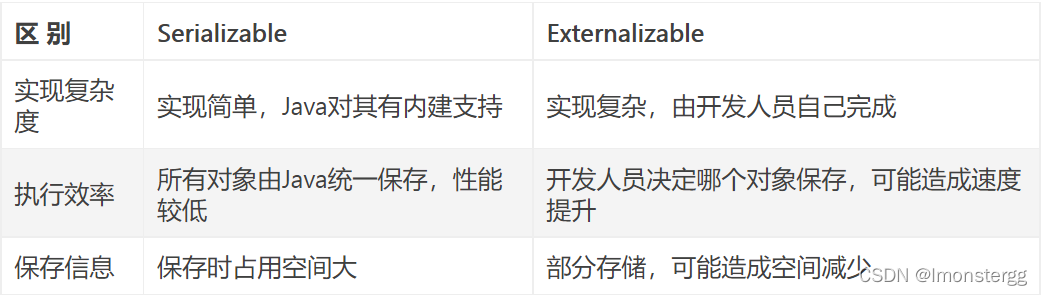
因此一般还是使用Serializable
关于writeObject() 与 readObject()
上面也说过了,在最简单的情况下 , 开发人员会使用 Serializable 类来实现序列化与反序列化 . 即使是使用Externalizable类该类也是继承自Serializable,而Serializable类的序列化与反序列化离不开 writeObject() 和 readObject() 两个方法.

从官方文档可以看出 , 在序列化和反序列化时需要实现上述两个方法 , 这两个方法的参数是ObjectOutputStream和ObjectInputStream类型的 . 下面来简单介绍下这个两个类 .
java.io.ObjectOutputStream和writeObject()
ObjectOutputStream 类会将支持 java.io.Serializable 接口的 Java对象( 包括部分图形对象 ) 的原始数据类型写入 OutputStream 中 . 然后使用 ObjectInputStream 类读取( 重构 )对象 .
值得一提的是 , 这里 Output 和 Input 都是针对 " 内存 " 来说的 . Output 即将 " 内存 " 中的 Java对象 传输到 " 文件流 " 或者 " 网络套接字流 " 中 , 而 Input 则是将 " 文件流 " 或 " 网络套接字流 " 中的数据加载到 " 内存 " 中 , 这个点初学者容易搞混 , 需要重点关注 .
这里总结一下也就是ObjectOutputStream通常会和FileOutputStream配合使用,FileInputStream和ObjectInputStream配合使用
java.io.ObjectOutputStream 类会通过 writeObject() 方法将 Java 对象写入到数据流中 .
这里要注意一点
writeObject()方法会将所有 对象的类 , 类签名 , 非瞬态和非静态字段的值 写入到数据流中
什么是类签名 ?
在开发 JNI( Java Native Interface , Java 本地接口 ) 时需要调用 Java 层的方法或创建引用 , 此时就会用到 Java 签名机制 .
比如基本数据类型的签名如下所示 :
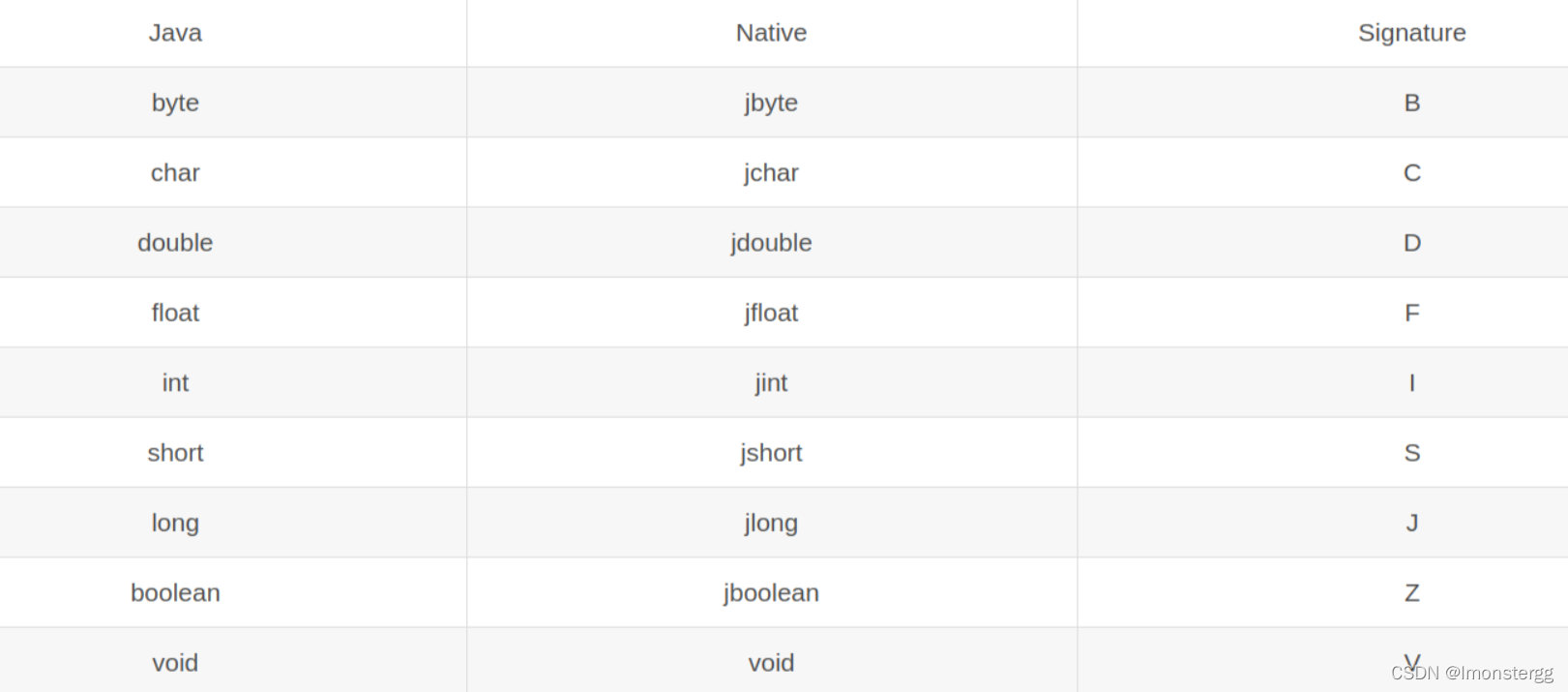
还有像 Ljava/lang/Class; , Ljava/lang/String; 等都是类签名 , 这些字符串在解析 Java 序列化数据时会用到 . 详细内容可以看看 java的数据类型的签名
什么是非瞬态 ?
瞬态变量( Transient ) 是一个 Java 关键词 , 它用于标记类的成员变量在持久化到字节流时不要被序列化 ; 在通过网络套接字流传输字节流时 , transient 关键词标记的成员变量不会被序列化 .
因此 , 如果仅想序列化某个类中部分变量 , 除了可以通过继承 Externalizable 接口来指定需要序列化的成员变量 ; 还可以将其他变量添加 transient 关键词 , 使得变量不被序列化 .
java.io.ObjectInputStream和readObject()
通过 ObjectOutputStream 类可以将对象写入数据流中 , 而通过 ObjectInputStream 类可以将数据流中的字节数组重构成对象 .
ObjectInputStream 类在重构对象时会从本地 JVM 虚拟机中加载对应的类 , 以确保重构时使用的类与被序列化的类是同一个 . 也就是说 : 反序列化进程的 JVM 虚拟机中必须加载被序列化的类 .
java.io.ObjectInputStream 类会通过 readObject() 方法将数据流中的序列化字符串重构成 Java 对象.
java.io.ObjectInputStream会通过readObject() 方法将读取序列化数据中各个字段的数据并分配给新对象的相应字段来恢复状态 .
需要注意的是 : readObject() 方法仅会反序列化 非静态变量 和 非瞬态变量 . 当读取到一个用 transient 修饰符修饰的变量时 , 将直接丢弃该变量 , 不再进行后续操作 .
此外 , 反序列化过程中 , 需要将重构的对象强制转换成预期的类型 , 比如 String 型变量就需要通过 (String) 修饰符强制转换成原来的类型 .
完整的 Java 序列化 / 反序列化流程
序列化过程
import java.io.*;
public class test {
public static void main(String[] args) throws IOException {
lmonstergg mst=new lmonstergg();
FileOutputStream aa=new FileOutputStream("/test.ser");
ObjectOutputStream bb=new ObjectOutputStream(aa);
System.out.println(bb);
bb.writeObject(mst);
aa.close();
bb.close();
}
}
import java.io.Serializable;
public class lmonstergg implements Serializable{
public String str="hello";
public String prt(String name)
{
String str=name+" sucessful";
return str;
}
}
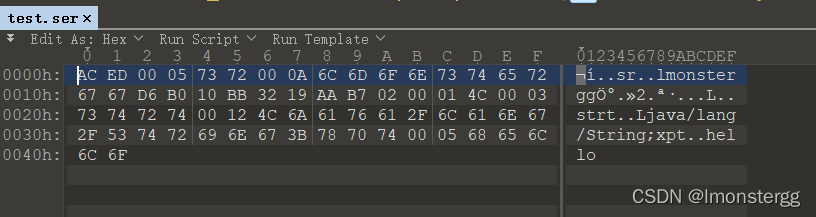
我这里放在windows上跑的,生成的ser文件我用了010editor查看
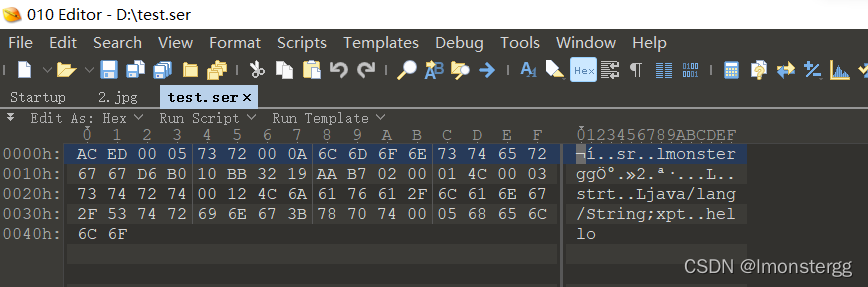
lmonstergg类类继承了 Serializable 接口 , 表明该类可以被序列化 ,该类中存在str变量和prt方法,他们被成功序列化
test类用于执行 Java 序列化过程 . 将 lmonstergg 类的实例对象序列化后输出到文件流中 , 并保存在 /test.ser 文件中 .
通过 010editor 工具查看 /test.ser 文件 , 可以看到其中存在 Java 反序列化数据 , 反序列化过程执行成功 .
反序列化过程
lmonstergg类不修改,修改test类代码如下
import java.io.*;
public class test {
public static void main(String[] args) throws IOException, ClassNotFoundException {
FileInputStream fin=new FileInputStream("/test.ser");
ObjectInputStream bin=new ObjectInputStream(fin);
lmonstergg obj=(lmonstergg) bin.readObject();
fin.close();
bin.close();
System.out.println(obj.str);
System.out.println(obj.prt("lmonstergg"));
}
}
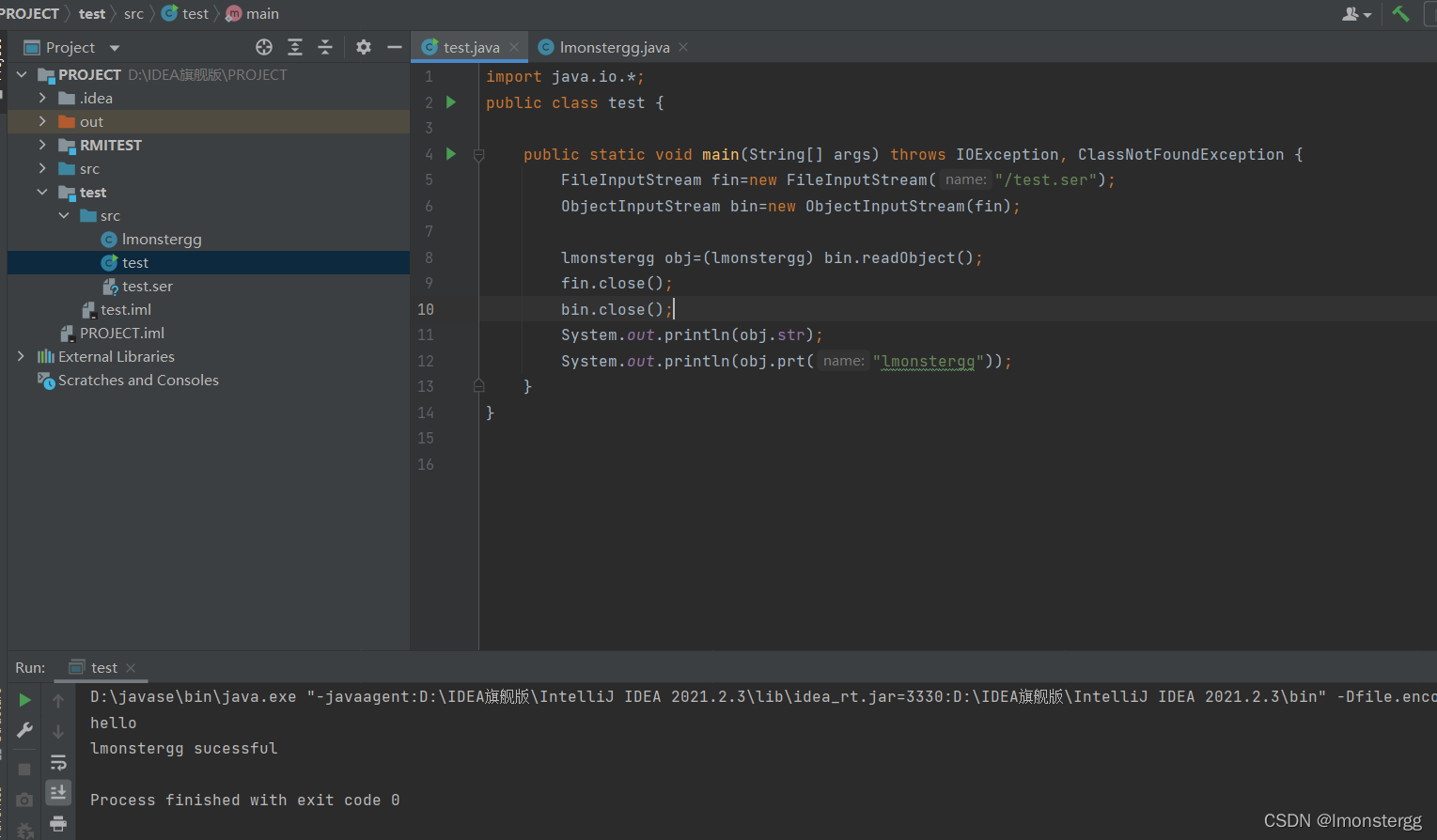
test 类打开文件流 , 读取 /test.ser 文件的内容 , 并进行反序列化操作 . 注意要进行强制转换 .
重构对象后 , 输出 lmonstergg 类 str 变量的值 , 并且执行 lmonstergg 类的 prt() 函数 . 全部执行成功 , 说明 lmonstergg 对象的相关字段全部被恢复了 .
总结
ObjectOutputStream通常会和FileOutputStream配合使用,FileInputStream和ObjectInputStream配合使用。
readObject和writeObject是序列化和反序列化的核心所在
Java 反序列化漏洞
这里看一张从大佬文章拿过来的图

图中已经说的比较清楚了 , 官方允许用户在被序列化的类中重写 readObject() 方法 , 重写后的方法将负责在反序列化时重构当前类对象 .
用户只需要在重写的 readObject() 方法中实现 defaultReadObject() 方法 , 就可以确保反序列化过程正常执行 . 至于添加的代码内容 , 官方没有做任何限制 .
举个例子,修改lmonstergg类如下
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
public class lmonstergg implements Serializable{
public String str="hello";
public String prt(String name)
{
String str=name+" sucessful";
return str;
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();;
System.out.println("had change");
}
}
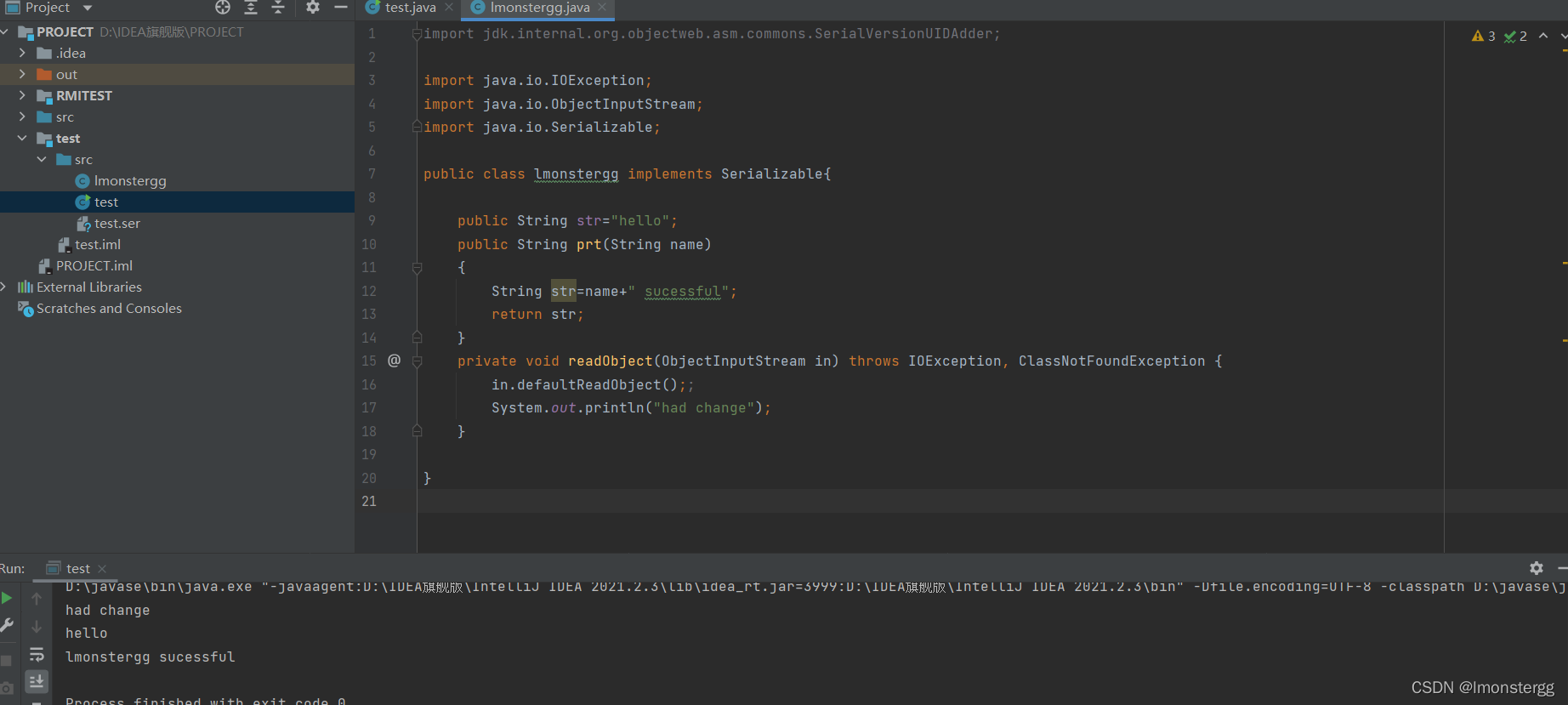
可以看到 , 在不修改其他代码的情况下 , 通过重写 readObject() 方法时添加其他代码 , 可以使得被添加的代码在反序列化过程中被执行
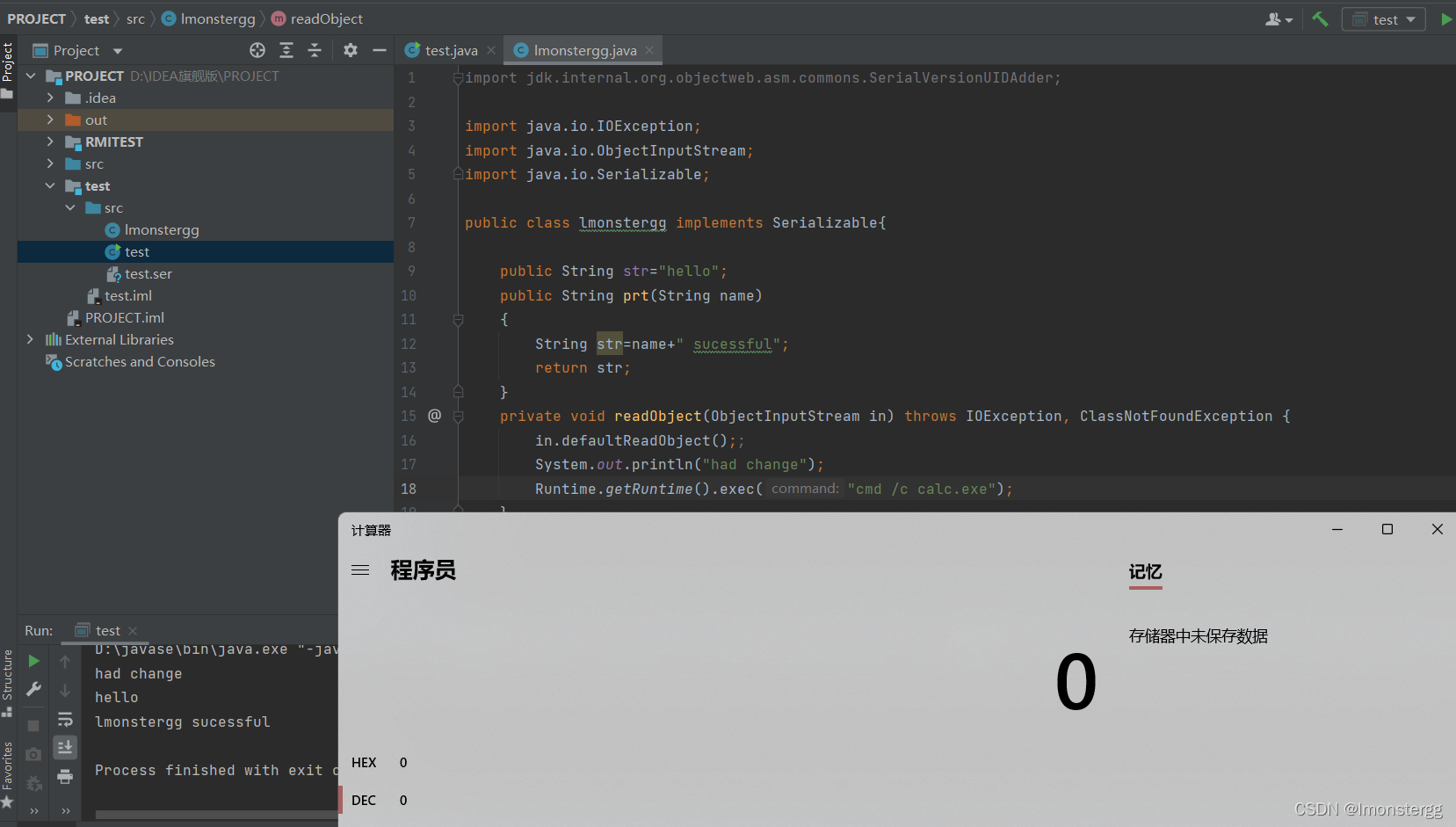
也就是说 , 如果我们在其中添加恶意代码 , 那么恶意代码也将被反序列化并执行 . 比如下面这个弹个计算器
Java 序列化数据分析和objectAnnotation
Java序列化数据的分析我就不细细记录了,感兴趣的可以看看大佬的原文
SerializationDumper这个工具可以帮助我们查看序列化的信息,接下来我们要借助这个工具看一些有意思的东西
我们还是用到上面序列化时用的代码生成test.ser文件,然后使用SerializationDumper查看该文件
java -jar SerializationDumper.jar -r test.ser
执行结果如下
STREAM_MAGIC - 0xac ed
STREAM_VERSION - 0x00 05
Contents
TC_OBJECT - 0x73
TC_CLASSDESC - 0x72
className
Length - 10 - 0x00 0a
Value - lmonstergg - 0x6c6d6f6e737465726767
serialVersionUID - 0xd6 b0 10 bb 32 19 aa b7
newHandle 0x00 7e 00 00
classDescFlags - 0x02 - SC_SERIALIZABLE
fieldCount - 1 - 0x00 01
Fields
0:
Object - L - 0x4c
fieldName
Length - 3 - 0x00 03
Value - str - 0x737472
className1
TC_STRING - 0x74
newHandle 0x00 7e 00 01
Length - 18 - 0x00 12
Value - Ljava/lang/String; - 0x4c6a6176612f6c616e672f537472696e673b
classAnnotations
TC_ENDBLOCKDATA - 0x78
superClassDesc
TC_NULL - 0x70
newHandle 0x00 7e 00 02
classdata
lmonstergg
values
str
(object)
TC_STRING - 0x74
newHandle 0x00 7e 00 03
Length - 5 - 0x00 05
Value - hello - 0x68656c6c6f
这时我们修改一下lmonstgg类的代码如下
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
public class lmonstergg implements Serializable{
public String str="hello";
public String prt(String name)
{
String str=name+" sucessful";
return str;
}
private void writeObject(java.io.ObjectOutputStream stream)
throws IOException{
stream.defaultWriteObject();
stream.writeObject("my lmonstergg");
}
}
这个代码修改了writeObject()方法,本来这个方法就是将lmonstergg类序列化写入test.ser,但现在writeObject()这个方法里面还调用了writeObject()方法,那不是又写一个对象进去了吗?
接下来我们通过SerializationDumper查看生成的test.ser,看看发生了什么
STREAM_MAGIC - 0xac ed
STREAM_VERSION - 0x00 05
Contents
TC_OBJECT - 0x73
TC_CLASSDESC - 0x72
className
Length - 10 - 0x00 0a
Value - lmonstergg - 0x6c6d6f6e737465726767
serialVersionUID - 0xd6 b0 10 bb 32 19 aa b7
newHandle 0x00 7e 00 00
classDescFlags - 0x03 - SC_WRITE_METHOD | SC_SERIALIZABLE
fieldCount - 1 - 0x00 01
Fields
0:
Object - L - 0x4c
fieldName
Length - 3 - 0x00 03
Value - str - 0x737472
className1
TC_STRING - 0x74
newHandle 0x00 7e 00 01
Length - 18 - 0x00 12
Value - Ljava/lang/String; - 0x4c6a6176612f6c616e672f537472696e673b
classAnnotations
TC_ENDBLOCKDATA - 0x78
superClassDesc
TC_NULL - 0x70
newHandle 0x00 7e 00 02
classdata
lmonstergg
values
str
(object)
TC_STRING - 0x74
newHandle 0x00 7e 00 03
Length - 5 - 0x00 05
Value - hello - 0x68656c6c6f
objectAnnotation
TC_STRING - 0x74
newHandle 0x00 7e 00 04
Length - 13 - 0x00 0d
Value - my lmonstergg - 0x6d79206c6d6f6e737465726767
TC_ENDBLOCKDATA - 0x78
从这里我们对比下前面就可以看出,classdata部分多了objectAnnotation这一块,里面就存着我们写入的值my lmonstergg
接下来我们看看反序列化,我们把上面反序列化的代码中lmonstergg类修改如下
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
public class lmonstergg implements Serializable{
public String str="hello";
public String prt(String name)
{
String str=name+" sucessful";
return str;
}
private void readObject(java.io.ObjectInputStream stream)
throws IOException, ClassNotFoundException{
stream.defaultReadObject();
System.out.println(stream.readObject());
}
}
这个代码修改了readObject()方法,我们看看执行结果
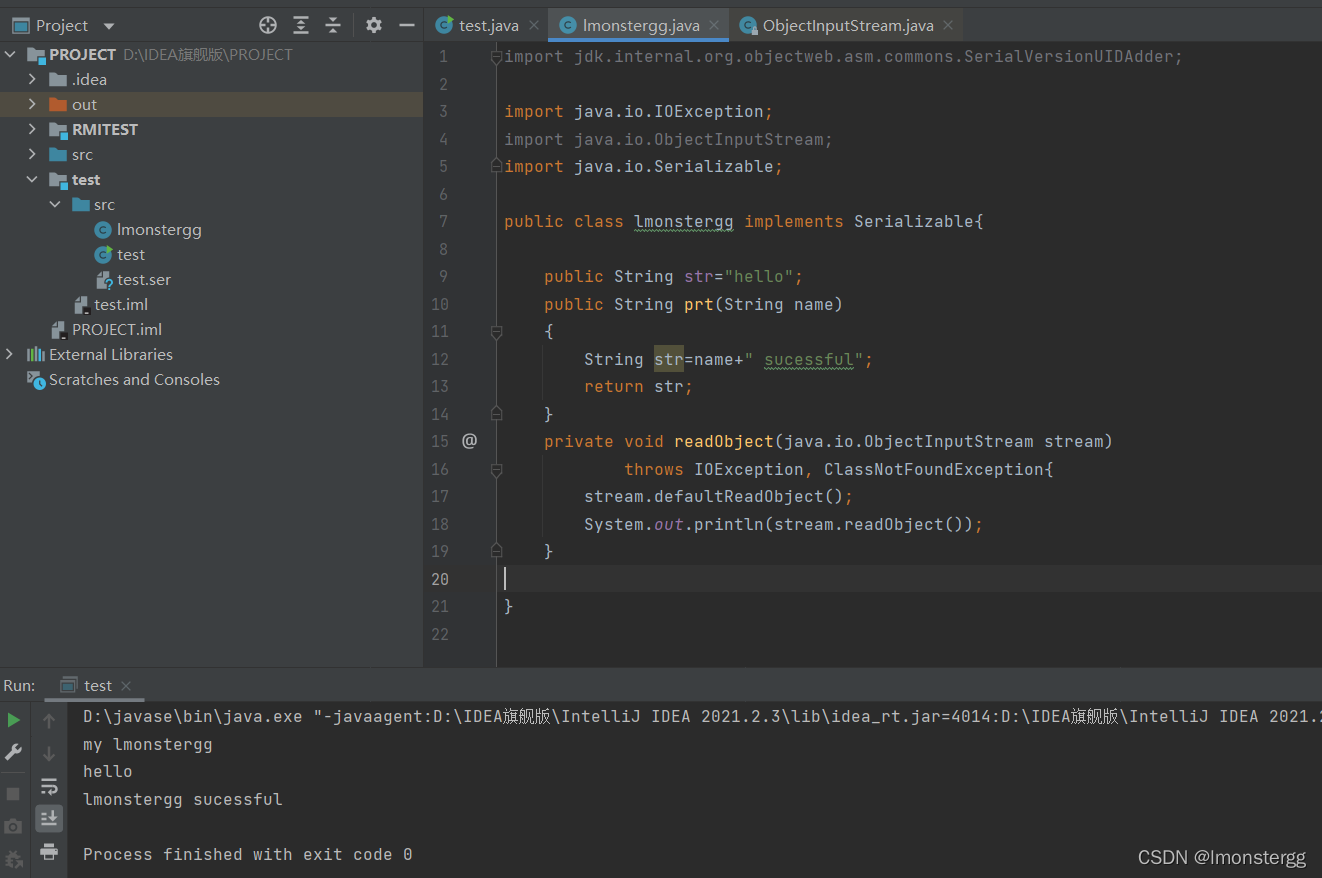
因此可以总结出
在自定义的writeObject中,调用传入的ObjectOutputStream的writeObject方法写入的对象,会写入到objectAnnotation中。
而自定义的readObject方法中,调用传入的ObjectInputStream的readObject方法读入的对象,则是objectAnnotation中存储的对象。
这个特性就让Java的开发变得非常灵活。比如后面将会讲到的HashMap,其就是将Map中的所有键、 值都存储在 objectAnnotation 中,而并不是某个具体属性里。
总结
Java反序列化的核心就是readObject和writeObject这两个函数,而在实现序列化与反序列之前通常需要继承 Serializable 类。而 ObjectOutputStream类会通过writeObject()方法将对象写入数据流中,ObjectInputStream 类会通过 readObject() 方法将数据流中的序列化字符串重构成 Java 对象
参考文章
Java 反序列化漏洞(3) – 初探 Java 反序列化漏洞以及序列化数据分析
Java 序列化和反序列化 学习笔记