
Java的疯狂内卷之分布式学习,提到分布式可能大家印象中就是只是面试题中问一问,只是背一背相关的面试题,并没有深入了解过。像分布式事务、分布式锁、分布式架构这些技术潮流指向的 “ 名词 ”, 我看网上并没有文章深入剖析和应用,于是就此本博主决定自己内卷,深入学习一下分布式系统。
分布式
1. 为什么要引入分布式架构?
1.1 单体架构概述
网上的大多数文章讲的很笼统,并不是很好理解,其实很简单。几乎99%的Java程序员都做过以SpringBoot框架为主的单体架构,我们的代码、业务逻辑都耦合在一起,代码只在同一个项目中完成,直接打成Jar包在服务器上部署就可以,部署时只用部署单个Jar包就可以、操作简单。这就是我们熟知的单体架构。
用一句话来概括:将业务的所有功能集中在一个项目中开发,打成一个包部署。
在一些小型应用的初期,访问量小的时候,这种架构的性价比还是比较高的,开发速度快,成本低,但是随着业务的发展,逻辑越来越复杂,代码量越来越大,代码的可读性和可维护性越来越低。用户的增加,访问量越来越多单体架构的应用并发能力十分有限。可能会有人想到将单体应用进行集群部署,并增加负载均衡服务器,再来个缓存服务器和文件服务器,数据库再搞个读写分离。这种架构如下图所示:
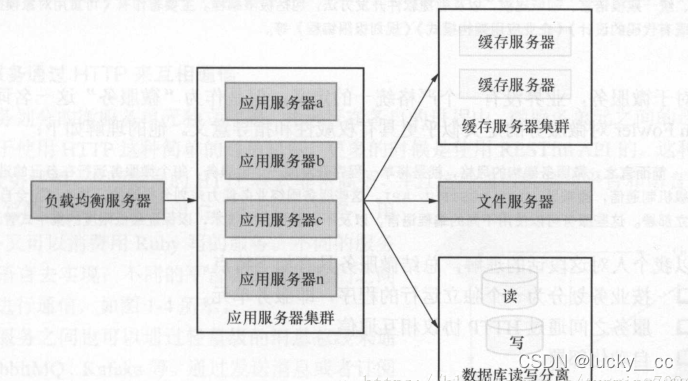
这种架构虽然有一定的并发能力,及应对一定复杂业务,但是依然没有改变系统为单体架构的事实。大量的业务必然会有大量的代码,代码得可读性和可维护性依然很差。如果面对海量的用户,它的并发能力依然不够。
1.2 单体架构的不足
1.项目过于臃肿 - 当大大小小的功能模块都集中在同一项目的时候,整个项目必然会变的臃肿,让开发者难以维护。
2.资源无法隔离 - 整个单体系统各个功能模块都依赖于同样的数据库,内存等资源,一旦某个功能模块对资源使用不当,整个系统都会被拖垮。
3.无法灵活扩展 - 当系统的访问量越来越大的时候,单个系统固然可以进行水平扩展,部署在多台机器上组成集群,但这种扩展并非灵活的扩展。只针对单个模块的扩展,单体架构是做不到的,比如我们现在的性能瓶颈是支付模块,希望只针对支付模块做水平扩展,这一点在单体系统是做不到的。
1.3 分布式架构
1.3.1 拆分 + 连接 是分布式系统的本质
所谓分布式,无非就是 将一个系统拆分成多个子系统并散布到不同设备“的过程而已
本质上而言,实现一个分布式系统,最核心的部分无非有两点:
1.如何拆分——可以有很多方式,核心依据一是业务需求,二是成本限制。这是实践中构建分布式系统时最主要的设计依据。
2.如何连接——光把系统拆开成 Process 还不够,关键是拆开后的 Process 之间还要能通信,因此涉及通信协议设计的问题,需要考虑的因素很多,好消息是这部分其实成熟的方案很多,SpringCloud微服务架构及其各种组件就是很好的体现。
1.3.2 为什么要使用分布式?
分布式系统并非灵丹妙药,解决问题的关键还是看你对问题本身的了解。通常我们需要使用分布式的常见理由是:
1.为了性能扩展 ——系统负载高,单台机器无法承载,希望通过使用多台机器来提高系统的负载能力。
例:对一个B2C(京东、淘宝)商城进行拆分,首页部分我们要考虑到高并发、高可用、搜索、缓存等等一系列的情况,需要把这个功能单独拆分出来,来扩展性能。
2.为了增强可靠性 ——软件不是完美的,网络不是完美的,甚至机器本身也不可能是完美的,随时可能会出错,为了避免故障,需要将业务分散开保留一定的冗余度。
在以提供 Service 为主的服务端软件开发过程中常常遇到这些问题。
一些分布式方案能解决你的问题,另一些却不能,要学会的其实是选择.
笼统的讨论分布式没有太大的意义,就如刚才所谈的,实际上分布式很容易实现,真正难的地方在于如何选择正确的分布方案。
例如,当你想要建立一个分布式的数据管理系统的时候,你就必须得面对“一致性”问题。如果你对数据一致性要求很高,你就不得不容忍一些缺陷例如规模伸缩困难;而如果你放弃它,你可以轻松伸缩规模,但你必须解决好由此带来的一系列数据不一致导致的问题。(CAP 问题)
分布式要考虑的问题有如下:
- 如何合理的拆分出子系统。
- 子系统之间如何通信。
- 通信过程的安全如何保障。
- 子系统扩展要如何设计。
- 子系统的可靠性要如何保证。
- 多个子系统之间相互通信交互数据,如何保证数据的一致性。
2. 如何实现分布式锁?
2.1 基于缓存(Redis等)实现分布式锁
在面试之前,确实只了解一些基本的分布式锁原理,即为如下Redis的命令和加锁原理。现在深入的用代码实践一下~
1. 选用Redis实现分布式锁原因:
(1)Redis有很高的性能;
(2)Redis命令对此支持较好,实现起来比较方便
2. 使用命令介绍:
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
(1)SETNX 给当前key加锁
SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
(2)expire 为当前key设置超时时间自动释放锁
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
(3)delete
delete key:删除key
3. 实现思想:
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
2.1.2 实现分布式锁场景应用
使用线程池实现库存递减的操作,实现结果如下:
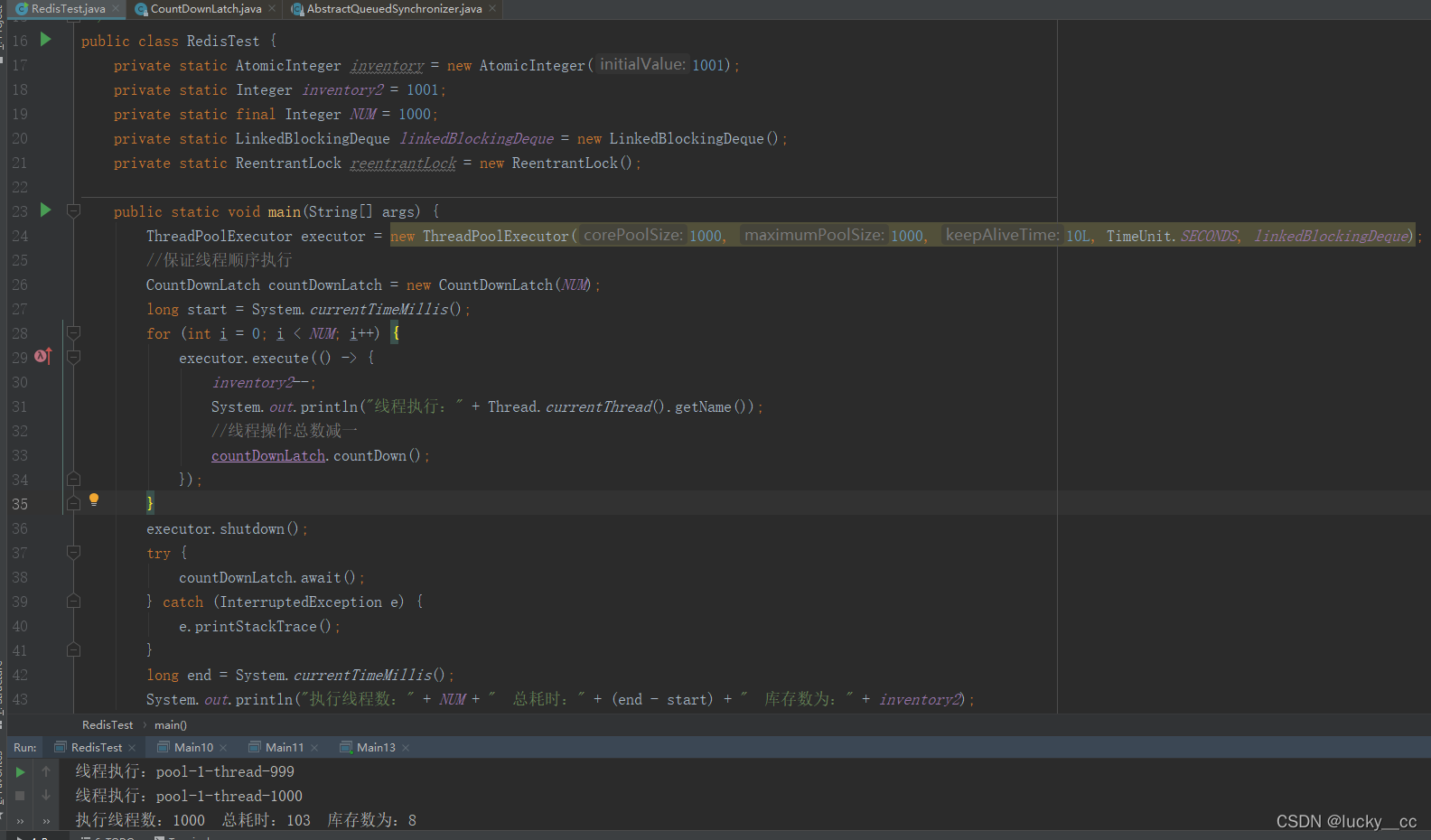
我创建了很多个线程去扣减库存inventory2,不出意外的库存扣减顺序变了,最终的结果也是不对的。
单机加synchronized或者Lock这些常规操作就不说了,结果肯定是对的。
现在我们考虑下AtomicInteger(原子操作类),它也可以保证结果是对的,可参照 AtomicInteger原子操作类原理进行了解,结果展示如下:
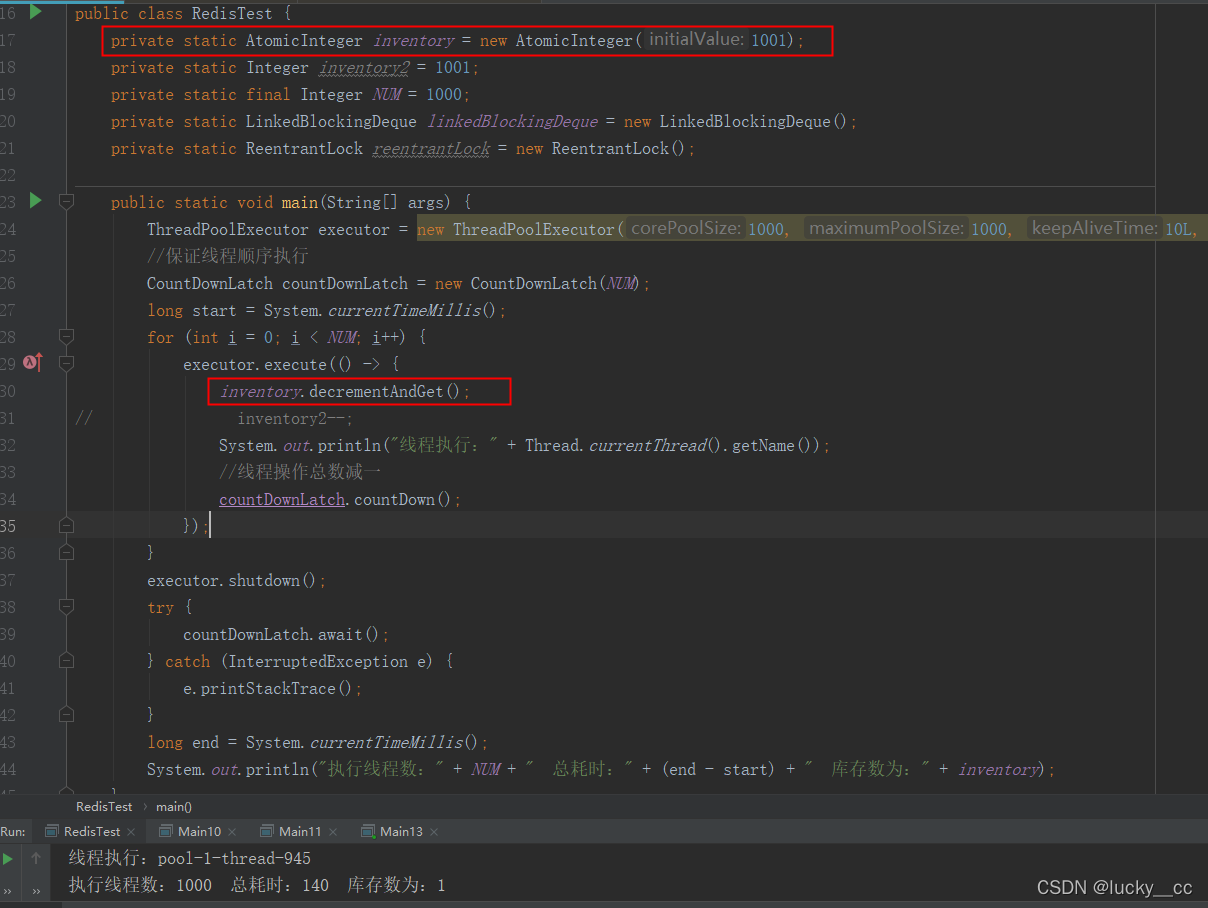
现在研究下分布式锁保证线程依次扣减的结果:
 现在把测试代码贴上,博主建议大家一定要手动敲一遍,要不然只凭眼睛看,是体会不到锁的乐趣的~
现在把测试代码贴上,博主建议大家一定要手动敲一遍,要不然只凭眼睛看,是体会不到锁的乐趣的~
package com.cc.demo.eureka.test;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.locks.ReentrantLock;
/**
* Description:
*
* @author chencongcong
* @date 2021/12/22 16:13
*/
public class RedisTest {
private static AtomicInteger inventory = new AtomicInteger(1001);
private static Integer inventory2 = 1001;
private static final Integer NUM = 1000;
private static LinkedBlockingDeque linkedBlockingDeque = new LinkedBlockingDeque();
private static ReentrantLock reentrantLock = new ReentrantLock();
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(1000, 1000, 10L, TimeUnit.SECONDS, linkedBlockingDeque);
//保证线程顺序执行
CountDownLatch countDownLatch = new CountDownLatch(NUM);
long start = System.currentTimeMillis();
for (int i = 0; i < NUM; i++) {
executor.execute(() -> {
//inventory.decrementAndGet();
reentrantLock.lock();
try {
inventory2--;
}finally {
reentrantLock.unlock();
}
System.out.println("线程执行:" + Thread.currentThread().getName());
//线程操作总数减一
countDownLatch.countDown();
});
}
executor.shutdown();
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("执行线程数:" + NUM + " 总耗时:" + (end - start) + " 库存数为:" + inventory2);
}
}
本部分内容是参考知乎的敖丙同学的文章深入学习实践的:如何用Redis实现分布式锁,本博主只增添了AtomicInteger(原子操作类),保证线程扣减顺序依次执行,结果正确的。
3. 如何保证 redis 和 数据库数据的一致性
3.1 需求起因
在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库。
这个业务场景,主要是解决读数据从Redis缓存,一般都是按照下图的流程来进行业务操作。
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存(Redis)和数据库(MySQL)间的数据一致性问题。
不管是先写MySQL数据库,再删除Redis缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。举一个例子:
1.如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
2.如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。
如来解决?这里给出两个解决方案,先易后难,结合业务和技术代价选择使用。
二、缓存和数据库一致性解决方案
3.2 解决办法
第一种方案:采用延时双删策略
在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。
伪代码如下:
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(500);
redis.delKey(key);
}
具体的步骤就是:
先删除缓存;再写数据库;休眠500毫秒;再次删除缓存。
那么,这个500毫秒怎么确定的,具体该休眠多久呢?
需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
当然这种策略还要考虑redis和数据库主从同步的耗时。最后的的写数据的休眠时间:则在读数据业务逻辑的耗时基础上,加几百ms即可。比如:休眠1秒。
设置缓存过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
该方案的弊端
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致,而且又增加了写请求的耗时。
第二种方案:异步更新缓存(基于订阅binlog的同步机制)
技术整体思路:
MySQL binlog 增量订阅消费+消息队列+增量数据更新到redis
读Redis:热数据基本都在Redis
写MySQL:增删改都是操作MySQL
更新Redis数据:MySQ的数据操作binlog,来更新到Redis
Redis更新
1)数据操作主要分为两大块:
一个是全量(将全部数据一次写入到redis)一个是增量(实时更新)
这里说的是增量,指的是mysql的update、insert、delete变更数据。
2)读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据。
这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。
这里可以结合使用canal(阿里的一款开源框架),通过该框架可以对MySQL的binlog进行订阅,而canal正是模仿了mysql的slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。
当然,这里的消息推送工具你也可以采用别的第三方:kafka、rabbitMQ等来实现推送更新Redis。
以上就是Redis和MySQL数据一致性详解。
4. 什么是分布式事务?
pending…