
Standalone运行模式
- 基本介绍
- 运行流程图
- 运行流程介绍
- 实现原理
- 环境搭建及案例
基本介绍
Standalone运行模式又称独立运行模式,它是是Spark自身实现的资源调度框架,可以单独部署到一个集群中,无依赖任何其他资源管理系统。
不使用其他调度工具时会存在单点故障,使用Zookeeper等可以解决;
该模式由Client、Master节点和 Worker节点组成,其中SparkContext 既可以运行在Master节点上,也可以运行在本地客户端。
运行流程图
当用 Spark-Shell交互式工具提交作业或者直接使用run-example脚本来运行示例时,SparkContext在 Master节点上运行;当使用Spark-Submit工具提交作业或者在Eclipse、IDEA等开发平台上运行Spark作业时,SparkContext是运行在本地客户端。
Worker节点可以通过ExecutorRunner运行在当前节点上的 CoarseGrainedExecutorBackend进程,每个Worker节点上存在一个或多个CoarseGrainedExecutorBackend进程,每个进程包含一个Executor对象。该对象持有一个线程池,每个线程可以执行一个任务。
运行流程如下图
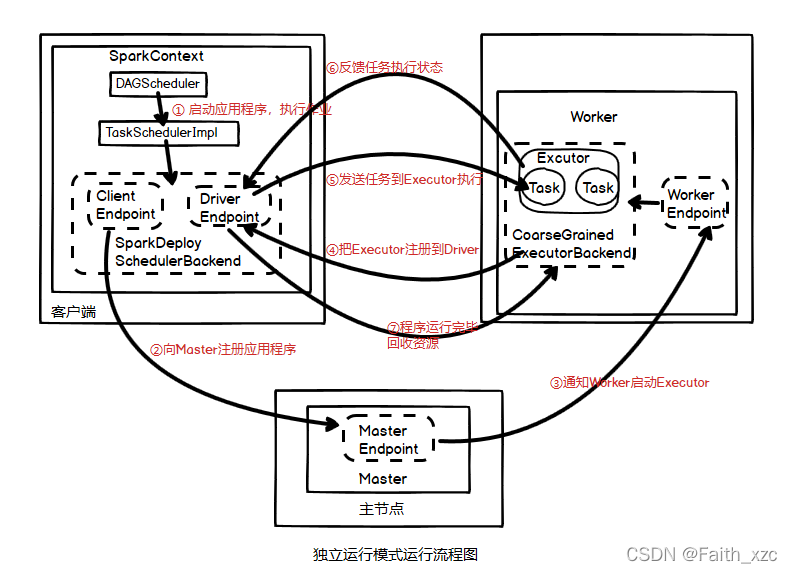
运行流程介绍
依据上面的运行流程图进行详细介绍运行步骤如下:
1.启动应用程序,执行作业
在 SparkContext启动过程中,先初始化 DAGScheduler和TaskSchedulerImpl两个调度器,同时初始化SparkDeploySchedulerBackend,并在其内部启动终端点 DriverEndpoint和 ClientEndpoint。
2.向Master注册程序
终端点ClientEndpoint向 Master注册应用程序,Master收到注册消息把该应用加入到等待运行应用列表中,等待由Mater分派给该应用程序Worker。
3.通知Work启动Executor
当应用程序获取到Worker时,Master 会通知 Worker中的终端点 WokerEndpoint 创建CoarseGrained-ExecutorBackend进程,在该进程中创建执行容器Executor。
4.把Executor注册到Driver
Executor创建完毕后发送消息给Master 和终端点DriverEndpoint,告知 Executor 已经创建完毕,在SparkContext成功注册后,等待接收从 Driver终端点发送执行任务的消息。
5.发送任务到Executor执行
SparkContext分配任务集给CoarseGrainedExecutorBackend执行,任务执行是在Executor按照一定调度策略进行的。
6.反馈任务状态
CoarseGrainedExecutorBackend在任务处理过程中,把处理任务的状态发送给SparkContext的终端点DriverEndpoint,SparkContext根据任务执行不同的结果进行处理。如果任务集处理完毕后,则会继续发送其他的任务集。
7.程序运行完毕,资源回收
应用程序运行完成后,SparkContext 会进行资源回收,先销毁在各 Worker 的CoarseGrainedExecutor-Backend进程,然后注销其自身。
实现原理
选择模式
在Spark选择模式的代码中,需要进行匹配:
//独立运行模式匹配字符串,以spark开头得字符串
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
//初始化TaskSchedulerImpl和SparkDeploySchedulerBackend
(backend, scheduler)
具体实现流程的代码参考Spark核心原理之作业执行原理
独立运行模式下类调用关系图如下
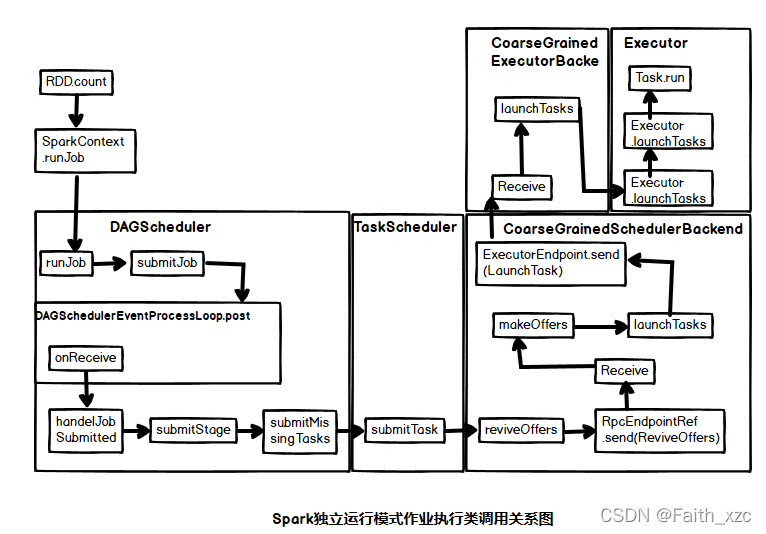
环境搭建及案例
环境搭建及案例