
第三卷 第四章 在ImageNet上训练AlexNet
在上一章中,我们详细讨论了 ImageNet 数据集;具体来说,数据集的目录结构和所使用的支持元文件为每个图像提供了类标签。 我们定义了两组文件:
1. 一个配置文件,允许我们在 ImageNet 上训练卷积神经网络时轻松创建新实验。
2. 一组实用程序脚本,用于准备将数据集从磁盘上的原始图像转换为有效打包的mxnet记录文件。
.rec 文件只需要生成一次——我们可以将这些记录文件重用于我们希望执行的任何 ImageNet 分类实验。
配置文件本身也是可以复用的。我们将对 VGGNet、GoogLeNet、ResNet 和 SqueezeNet 使用相同的配置文件——配置文件的唯一方面需要在以下情况下更改 在 ImageNet 上训练一个新网络是:
1. 网络架构的名称(嵌入在配置文件名中)。
2.批量大小。
3. 用于训练网络的 GPU 数量(如果适用)。
在本章中,我们将首先使用 mxnet 库来实现 AlexNet 架构。 我们已经在第二卷的第10章中使用 Keras 实现了AlexNet。 正如您将看到的,mxnet 和 Keras 之间有许多相似之处,这使得在两个库之间移植实现变得非常简单。从那里,我将演示如何在ImageNet数据集上训练AlexNet。
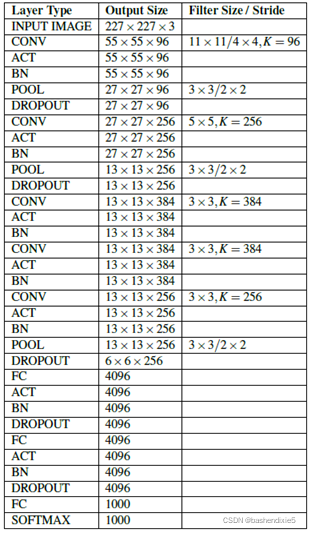
1、实施AlexNet
创建mxalexnet.py文件。
# import the necessary packages
import mxnet as mx
class MxAlexNet:
@staticmethod
def build(classes):
# data input
data = mx.sym.Variable("data")
# Block #1: first CONV => RELU => POOL layer set
conv1_1 = mx.sym.Convolution(data=data, kernel=(11, 11), stride=(4, 4), num_filter = 96)
act1_1 = mx.sym.LeakyReLU(data=conv1_1, act_type="elu")
bn1_1 = mx.sym.BatchNorm(data=act1_1)
pool1 = mx.sym.Pooling(data=bn1_1, pool_type="max", kernel=(3, 3), stride=(2, 2))
do1 = mx.sym.Dropout(data=pool1, p=0.25)
# 使用标准ReLU而不是ELU
# # Block #1: first CONV => RELU => POOL layer set
# conv1_1 = mx.sym.Convolution(data=data, kernel=(11, 11),stride = (4, 4), num_filter = 96)
# bn1_1 = mx.sym.BatchNorm(data=conv1_1)
# act1_1 = mx.sym.Activation(data=bn1_1, act_type="relu")
# pool1 = mx.sym.Pooling(data=act1_1, pool_type="max",kernel = (3, 3), stride = (2, 2))
# do1 = mx.sym.Dropout(data=pool1, p=0.25)
# 保留了 ReLU 激活,但交换了批量标准化的顺序
# # Block #1: first CONV => RELU => POOL layer set
# conv1_1 = mx.sym.Convolution(data=data, kernel=(11, 11),stride = (4, 4), num_filter = 96)
# act1_1 = mx.sym.Activation(data=conv1_1, act_type="relu")
# bn1_1 = mx.sym.BatchNorm(data=act1_1)
# pool1 = mx.sym.Pooling(data=bn1_1, pool_type="max",kernel = (3, 3), stride = (2, 2))
# do1 = mx.sym.Dropout(data=pool1, p=0.25)
# Block #2: second CONV => RELU => POOL layer set
conv2_1 = mx.sym.Convolution(data=do1, kernel=(5, 5), pad=(2, 2), num_filter=256)
act2_1 = mx.sym.LeakyReLU(data=conv2_1, act_type="elu")
bn2_1 = mx.sym.BatchNorm(data=act2_1)
pool2 = mx.sym.Pooling(data=bn2_1, pool_type="max", kernel = (3, 3), stride = (2, 2))
do2 = mx.sym.Dropout(data=pool2, p=0.25)
# Block #3: (CONV => RELU) * 3 => POOL
conv3_1 = mx.sym.Convolution(data=do2, kernel=(3, 3), pad=(1, 1), num_filter=384)
act3_1 = mx.sym.LeakyReLU(data=conv3_1, act_type="elu")
bn3_1 = mx.sym.BatchNorm(data=act3_1)
conv3_2 = mx.sym.Convolution(data=bn3_1, kernel=(3, 3), pad=(1, 1), num_filter=384)
act3_2 = mx.sym.LeakyReLU(data=conv3_2, act_type="elu")
bn3_2 = mx.sym.BatchNorm(data=act3_2)
conv3_3 = mx.sym.Convolution(data=bn3_2, kernel=(3, 3), pad=(1, 1), num_filter=256)
act3_3 = mx.sym.LeakyReLU(data=conv3_3, act_type="elu")
bn3_3 = mx.sym.BatchNorm(data=act3_3)
pool3 = mx.sym.Pooling(data=bn3_3, pool_type="max", kernel=(3, 3), stride = (2, 2))
do3 = mx.sym.Dropout(data=pool3, p=0.25)
# Block #4: first set of FC => RELU layers
flatten = mx.sym.Flatten(data=do3)
fc1 = mx.sym.FullyConnected(data=flatten, num_hidden=4096)
act4_1 = mx.sym.LeakyReLU(data=fc1, act_type="elu")
bn4_1 = mx.sym.BatchNorm(data=act4_1)
do4 = mx.sym.Dropout(data=bn4_1, p=0.5)
# Block #5: second set of FC => RELU layers
fc2 = mx.sym.FullyConnected(data=do4, num_hidden=4096)
act5_1 = mx.sym.LeakyReLU(data=fc2, act_type="elu")
bn5_1 = mx.sym.BatchNorm(data=act5_1)
do5 = mx.sym.Dropout(data=bn5_1, p=0.5)
# softmax classifier
fc3 = mx.sym.FullyConnected(data=do5, num_hidden=classes)
model = mx.sym.SoftmaxOutput(data=fc3, name="softmax")
# return the network architecture
return model2、训练AlexNet
创建train_alexnet.py文件。
# import the necessary packages
import imagenet_alexnet_config as config
from mxalexnet import MxAlexNet
import mxnet as mx
import argparse
import logging
import json
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--checkpoints", required=True, help="path to output checkpoint directory")
ap.add_argument("-p", "--prefix", required=True, help="name of model prefix")
ap.add_argument("-s", "--start-epoch", type=int, default=0, help="epoch to restart training at")
args = vars(ap.parse_args())
# set the logging level and output file
logging.basicConfig(level=logging.DEBUG,filename="training_{}.log".format(args["start_epoch"]),filemode="w")
# load the RGB means for the training set, then determine the batch
# size
means = json.loads(open(config.DATASET_MEAN).read())
batchSize = config.BATCH_SIZE * config.NUM_DEVICES
# construct the training image iterator
trainIter = mx.io.ImageRecordIter(
path_imgrec=config.TRAIN_MX_REC,
data_shape=(3, 227, 227),
batch_size=batchSize,
rand_crop=True,
rand_mirror=True,
rotate=15,
max_shear_ratio=0.1,
mean_r=means["R"],
mean_g=means["G"],
mean_b=means["B"],
preprocess_threads=config.NUM_DEVICES * 2)
# construct the validation image iterator
valIter = mx.io.ImageRecordIter(
path_imgrec=config.VAL_MX_REC,
data_shape=(3, 227, 227),
batch_size=batchSize,
mean_r=means["R"],
mean_g=means["G"],
mean_b=means["B"])
# initialize the optimizer
opt = mx.optimizer.SGD(learning_rate=1e-2, momentum=0.9, wd=0.0005, rescale_grad=1.0 / batchSize)
# # initialize the optimizer
# opt = mx.optimizer.SGD(learning_rate=1e-3, momentum=0.9, wd=0.0005, rescale_grad=1.0 / batchSize)
# construct the checkpoints path, initialize the model argument and
# auxiliary parameters
checkpointsPath = os.path.sep.join([args["checkpoints"], args["prefix"]])
argParams = None
auxParams = None
# if there is no specific model starting epoch supplied, then
# initialize the network
if args["start_epoch"] <= 0:
# build the LeNet architecture
print("[INFO] building network...")
model = MxAlexNet.build(config.NUM_CLASSES)
# otherwise, a specific checkpoint was supplied
else:
# load the checkpoint from disk
print("[INFO] loading epoch {}...".format(args["start_epoch"]))
model = mx.model.FeedForward.load(checkpointsPath,args["start_epoch"])
# update the model and parameters
argParams = model.arg_params
auxParams = model.aux_params
model = model.symbol
# compile the model
model = mx.model.FeedForward(
ctx=[mx.gpu(0)],
#ctx=[mx.gpu(1), mx.gpu(2), mx.gpu(3)],
symbol=model,
initializer=mx.initializer.Xavier(),
arg_params=argParams,
aux_params=auxParams,
optimizer=opt,
num_epoch=90,
begin_epoch=args["start_epoch"])
# initialize the callbacks and evaluation metrics
batchEndCBs = [mx.callback.Speedometer(batchSize, 500)]
epochEndCBs = [mx.callback.do_checkpoint(checkpointsPath)]
metrics = [mx.metric.Accuracy(), mx.metric.TopKAccuracy(top_k=5), mx.metric.CrossEntropy()]
# train the network
print("[INFO] training network...")
model.fit(
X=trainIter,
eval_data=valIter,
eval_metric=metrics,
batch_end_callback=batchEndCBs,
epoch_end_callback=epochEndCBs)3、验证AlexNet
创建test_alexnet.py文件。
# import the necessary packages
import imagenet_alexnet_config as config
import mxnet as mx
import argparse
import json
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--checkpoints", required=True, help="path to output checkpoint directory")
ap.add_argument("-p", "--prefix", required=True, help="name of model prefix")
ap.add_argument("-e", "--epoch", type=int, required=True, help="epoch # to load")
args = vars(ap.parse_args())
# load the RGB means for the training set
means = json.loads(open(config.DATASET_MEAN).read())
# construct the testing image iterator
testIter = mx.io.ImageRecordIter(
path_imgrec=config.TEST_MX_REC,
data_shape=(3, 227, 227),
batch_size=config.BATCH_SIZE,
mean_r=means["R"],
mean_g=means["G"],
mean_b=means["B"])
# load the checkpoint from disk
print("[INFO] loading model...")
checkpointsPath = os.path.sep.join([args["checkpoints"], args["prefix"]])
model = mx.model.FeedForward.load(checkpointsPath, args["epoch"])
# compile the model
model = mx.model.FeedForward(
ctx=[mx.gpu(0)],
symbol=model.symbol,
arg_params=model.arg_params,
aux_params=model.aux_params)
# make predictions on the testing data
print("[INFO] predicting on test data...")
metrics = [mx.metric.Accuracy(), mx.metric.TopKAccuracy(top_k=5)]
(rank1, rank5) = model.score(testIter, eval_metric=metrics)
# display the rank-1 and rank-5 accuracies
print("[INFO] rank-1: {:.2f}%".format(rank1 * 100))
print("[INFO] rank-5: {:.2f}%".format(rank5 * 100))4、AlexNet实验
在评估和比较AlexNet性能时,我们通常使用Caffe提供的BVLC AlexNet 实现,而不是原始的 AlexNet实现。 这种比较有多种原因,包括Krizhevsky等人使用的不同数据增强。 以及(现已弃用)本地响应归一化层 (LRN) 的使用。 此外,AlexNet 的“CaffeNet”版本往往更易于科学界访问。 在本节的其余部分,我将把我的结果与 CaffeNet 基准进行比较,但仍然参考原始的 Krizhevsky 等人的论文。
4.1 实验1
第一个AlexNet实验中,我决定凭经验证明为什么我们在激活之后而不是在激活之前放置批标准化层。我还使用标准ReLU而不是ELU来获得模型性能的基线(Krizhevsky等人在他们的实验中使用了ReLU)。因此,我修改了本章前面详述的 mxalexnet.py文件,以反映批量规范化和激活更改,其示例如下所示:
# Block #1: first CONV => RELU => POOL layer set
conv1_1 = mx.sym.Convolution(data=data, kernel=(11, 11),stride = (4, 4), num_filter = 96)
bn1_1 = mx.sym.BatchNorm(data=conv1_1)
act1_1 = mx.sym.Activation(data=bn1_1, act_type="relu")
pool1 = mx.sym.Pooling(data=act1_1, pool_type="max",kernel = (3, 3), stride = (2, 2))
do1 = mx.sym.Dropout(data=pool1, p=0.25)
使用 SGD 训练 AlexNet,初始学习率为 1e-2,动量项为 0.9,L2 权重衰减为 0.0005。
大约每 10 个 epoch 监控一次进度。 我看到新的深度学习从业者犯的最严重的错误之一是过于频繁地检查他们的训练图。 在大多数情况下,您需要 10-15个epoch的上下文才能做出网络确实过度拟合、欠拟合等的决定。在70个epoch 之后,我绘制了我的训练损失和准确度(图 6.1),top-eft).此时,验证和训练的准确率基本上停滞在约49-50% ,这清楚地表明可以降低学习率以进一步提高准确率。
因此,我通过编辑 train_alexnet.py 的第 53 和 54 行将我的学习率更新为 1e-3:
# initialize the optimizer
opt = mx.optimizer.SGD(learning_rate=1e-3, momentum=0.9, wd=0.0005, rescale_grad=1.0 / batchSize)
请注意学习率是如何从 1e-2 降低到 1e-3,但所有其他 SGD 参数都保持不变。 然后我使用以下命令从 epoch 50 重新开始训练:
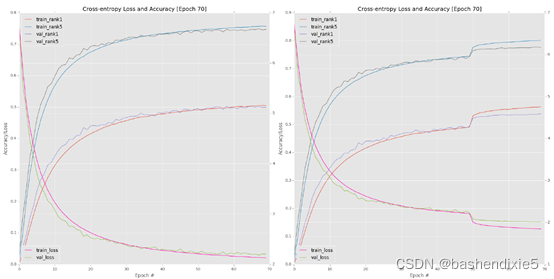
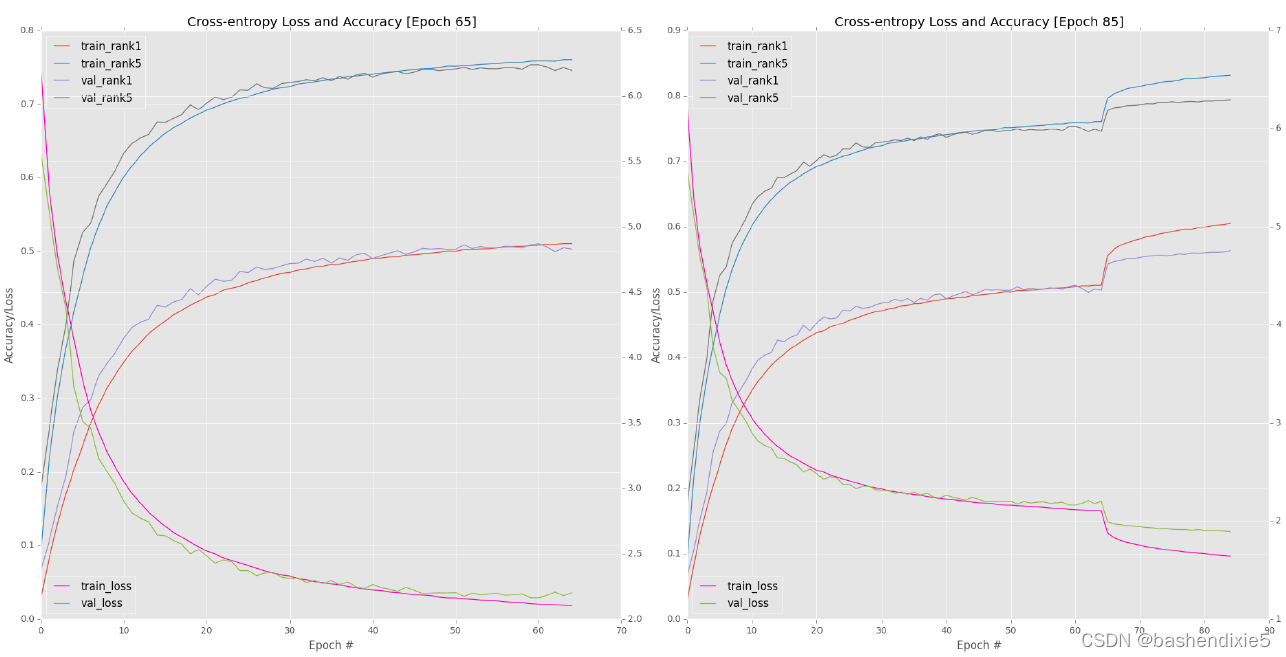
监视AlexNet的进展,直到第70epoch(图6.1,右上角)。您应该从该图中检查的第一个关键结论是,将我的学习率从1e-2降低到1e-3是如何导致准确度的急剧上升和第50个时期之后损失的急剧下降——这种准确度的提高和损失的下降是 当您在大型数据集上训练深度神经网络时,这是正常的。通过降低学习率,我们允许我们的网络下降到较低的损失区域,因为之前学习率太大,优化器无法找到这些区域。请记住,训练深度学习网络的目标不一定是找到全局最小值甚至局部最小值;而不是简单地找到一个损失足够低的区域。
然而,在后期,我开始注意到验证损失/准确度的停滞(尽管训练准确度/损失继续提高)。 这种停滞往往是过度拟合开始发生的明显迹象,但验证和训练损失之间的差距是可以接受的,所以我并不太担心。我将我的学习率更新为 1e-4(同样,通过编辑 train_alexnet.py的第 53 和 54 行)并从 epoch 65 重新开始训练:
![]()
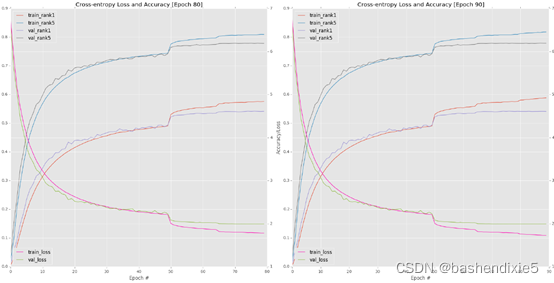
验证损失/准确性略有改善,但此时学习率开始变得太小——此外,我们开始过度拟合训练数据(图 6.1,左下角)。
最终允许我的网络使用 1e-5 学习率训练 10 个以上的 epochs (80-90):

图 6.1(右下)包含最后十个时期的结果图。 在第 90 期之后的进一步训练是不必要的,因为验证损失/准确性已经停止改善,而训练损失继续下降,使我们面临过度拟合的风险。 在 epoch 90 结束时,我在验证数据上获得了 54.14% 的 rank-1 准确率和 77.90% 的 rank-5 准确率。 对于第一个实验来说,这种准确度是非常合理的,但并不完全符合我对 AlexNet 级性能的期望,BVLC CaffeNet 参考模型报告说,该性能大约为 57% rank-1 准确度和 80% rank-5 准确度。
4.2 实验2
这个实验的目的是建立在前一个实验的基础上,并展示为什么我们在激活之后放置批量归一化层。 我保留了 ReLU 激活,但交换了批量标准化的顺序,如以下代码块所示:
# 保留了 ReLU 激活,但交换了批量标准化的顺序
# Block #1: first CONV => RELU => POOL layer set
conv1_1 = mx.sym.Convolution(data=data, kernel=(11, 11),stride = (4, 4), num_filter = 96)
act1_1 = mx.sym.Activation(data=conv1_1, act_type="relu")
bn1_1 = mx.sym.BatchNorm(data=act1_1)
pool1 = mx.sym.Pooling(data=bn1_1, pool_type="max",kernel = (3, 3), stride = (2, 2))
do1 = mx.sym.Dropout(data=pool1, p=0.25)
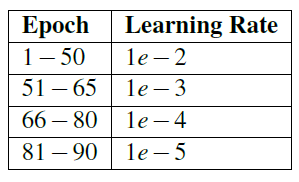
同样,我使用了与SGD完全相同的优化器参数,初始学习率为1e-2,动量为0.9,L2权重衰减为0.0005。表6.3包括我的时代和相关的学习率计划。我开始使用以下命令训练 AlexNet:
![]()
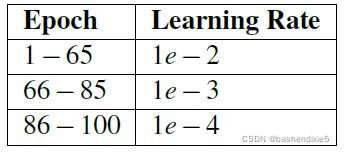
表 6.3:在 ImageNet 上为实验 #2 和实验 #3 训练 AlexNet 时使用的学习率计划。
在 epoch 65 左右,我注意到验证损失和准确性停滞不前(图 6.2,左上角)。 因此,我停止训练,将我的学习率调整为 1e-3,然后从第 65 个 epoch 开始重新开始训练:

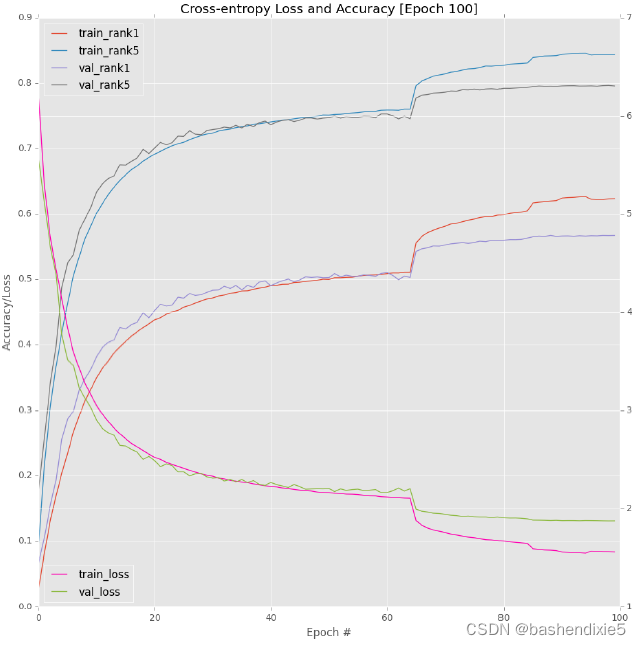
同样,当验证准确率/损失平稳时,我们可以通过降低学习率看到准确率的特征性跳跃(图 6.2,右上角)。 在第 85 个时期,我再次降低了我的学习率,这次从 1e-3 降低到 1e-4,并允许网络再训练 15 个时期,之后验证损失/准确性停止提高(图 6.2,底部)。
检查实验的日志,注意到 rank-1 准确度是 56.72%,rank-5 准确度是 79.62%,比我之前在激活之前放置批量归一化层的实验要好得多。 此外,这些结果完全在真实 AlexNet 级性能的统计范围内。
4.3 实验3
鉴于我之前的实验表明在激活后放置批量标准化会产生更好的结果,我决定用 ELU 激活替换标准 ReLU 激活。 根据我的经验,用ELU 替换 ReLU 通常可以使您在 ImageNet 数据集上的分类准确度提高 1-2%。 因此,我的 CONV => RELU 块现在变为:
# Block #1: first CONV => RELU => POOL layer set
conv1_1 = mx.sym.Convolution(data=data, kernel=(11, 11), stride=(4, 4), num_filter = 96)
act1_1 = mx.sym.LeakyReLU(data=conv1_1, act_type="elu")
bn1_1 = mx.sym.BatchNorm(data=act1_1)
pool1 = mx.sym.Pooling(data=bn1_1, pool_type="max", kernel=(3, 3), stride=(2, 2))
do1 = mx.sym.Dropout(data=pool1, p=0.25)
请注意在激活之后如何放置批量归一化层以及如何将ELU替换为ReLU。 在这个实验中,我使用了与前两次试验完全相同的SGD优化器参数。 我也遵循了第二个实验(表 6.3)中相同的学习率计划。
要复制我的实验,您可以使用以下命令:


第一个命令从第一个 epoch 开始训练,初始学习率为 1e-2。第二个命令在第 65 个 epoch 重新开始训练,使用学习率为 1e-3。 最后一个命令在第 85 个时期重新开始训练,学习率为 1e-4。
训练和验证损失/准确度的完整图可以在图 6.3 中看到。 同样,您可以看到在第 65 和 85 轮时期将学习率调整一个数量级的明显特征标记,随着学习率降低,跳跃变得不那么明显。 我不想训练过去 100 纪元,因为 AlexNet 显然开始过度拟合训练数据,而验证准确率/损失仍然停滞不前。 这个差距越大,过度拟合就越严重,因此我们应用“早期停止”正则化标准来防止进一步过度拟合。
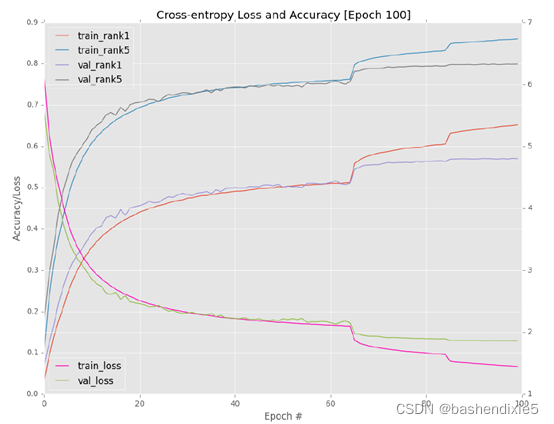
检查第 100 个时期的准确度,我发现我在验证数据集上获得了 57.00% rank-1 准确度和 79.52% rank-5 准确度。 这个结果只比我的第二个实验好一点,但非常有趣的是,当我使用 test_alexnet.py 脚本在测试集上进行评估时会发生什么:

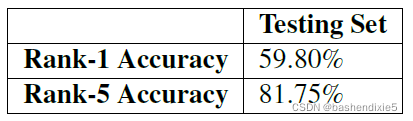
我在表 6.4 中总结了结果。 在这里你可以看到,我在测试集上获得了 59.80% rank-1 和 81.75% rank-5 准确率,当然高于大多数独立论文和出版物报告的 AlexNet 级准确率。 为了您的方便,我在您下载的 ImageNet Bundle 中包含了这个 AlexNet 实验的权重。
总的来说,本节的目的是让您了解在ImageNet数据集上获得性能合理的模型所需的实验类型。实际上,我的实验室日志包含25个独立的AlexNet+ImageNet实验,太多了,无法包含在本书中。相反,我选择了最能代表我对网络架构和优化器所做的重要更改的那些。 请记住,对于大多数深度学习问题,在获得在验证和测试数据上均表现良好的模型之前,您将运行10-100次(在某些情况下甚至更多)实验。
深度学习不像其他编程领域,你编写一个函数就可以永远运行。 相反,有许多需要微调的地方。调整参数后,您将获得性能良好的 CNN 奖励,但在那之前,请耐心等待,并记录您的结果! 记下哪些行得通,哪些行不通是非常宝贵的——这些笔记将使您能够反思自己的实验并确定新的追求途径。
5、小结
在本章中,我们使用mxnet库实现了AlexNet架构,然后在ImageNet数据集上对其进行了训练。本章很长,因为我们需要全面查看AlexNet架构、训练脚本和评估脚本。现在我们已经定义了我们的训练和评估Python脚本,我们将能够在未来的实验中重用它们,使训练和评估变得更加容易——我们的主要任务是实现实际的网络架构。
我们进行的实验使我们能够确定两个重要的要点:
1. 在大多数情况下,在激活之后(而不是之前)进行批量归一化将导致更高的分类准确率/更低的损失。
2. 将 ReLU 替换为 ELU 可以让您在分类准确度上有小幅提升。
总体而言,我们能够在 ImageNet 上获得 59.80% rank-1 和 81.75% rank-5 准确率,优于用于对 AlexNet 进行基准测试的标准 Caffe 参考模型。