目录
一、什么是正则表达式
1.创建正则表达式
2.测试正则表达式
二、正则表达式中的特殊字符
1.正则表达式的组成
2.边界符
3.字符类
4.量词符
5.预定义类
三、String类中的方法
1.match()方法;
2.search()方法
3、split()方法
4、replace()方法
一、什么是正则表达式
是用于匹配字符串中字符组合的模式。在 JavaScript中,正则表达式也是对象。
正则表通常被用来检索、替换那些符合某个模式(规则)的文本,例如验证表单:用户名表单只能输入英文字母、数字或者下划线, 昵称输入框中可以输入中文(匹配)。此外,正则表达式还常用于过滤掉页面内容中的一些敏感词(替换),或从字符串中获取我们想要的特定部分(提取)等 。
1.创建正则表达式
通常有两种方式可以创建正则表达式
1.通过调用RegExp对象构造函数创建;
var 变量名 = new RegExp(/表达式/); 2.通过字面量创建
var 变量名 = /表达式/;
2.测试正则表达式
test() 正则对象方法,用于检测字符串是否符合该规则,该对象会返回 true 或 false,其参数是测试字符串。
var str = '123'
var reg1 = new RegExp(/123/);
var reg2 = /abc/;
console.log(reg1.test(str)) ;
console.log(reg2.test(str)) ;
给定一个正则表达式var reg1 = /123/,判断我们输入的字符串str是否符合规则。
打印结果为:

str它符合了reg1但是没有匹配上reg2;
二、正则表达式中的特殊字符
1.正则表达式的组成
一个正则表达式可以由简单的字符构成,比如 /abc/,也可以是简单和特殊字符的组合,比如 /ab*c/ 。其中特殊字符也被称为元字符,在正则表达式中是具有特殊意义的专用符号,如 ^ 、$ 、+ 等。
2.边界符
顾名思义边界符就是正则表达式中的边界符(位置符)用来提示字符所处的位置
| 边界符 | 说明 |
| ^ | 表示匹配行首的文本 |
| $ | 表示匹配行尾的文本 |
如果 ^ 和 $ 在一起,表示必须是精确匹配
3.字符类
字符类表示有一系列字符可供选择,只要匹配其中一个就可以了。所有可供选择的字符都放在方括号内。
| 字符 | 说明 |
|---|---|
| [] | /[abc]/.test('andy')字符串只要包含abc中任意一个字符,都返回true。 |
| [-] | 方括号内部加上 - 表示范围, |
| [^] | 方括号内部加上 ^ 表示取反,只要包含方括号内的字符,都返回 false 。 |
4.量词符
用来设定某个模式出现的次数。
| 字符 | 说明 | 示例 | 结果 |
| ? | 匹配?前面的字符零次或一次 | hi?t | 可匹配ht和hit |
| + | 匹配+前面的字符一次或多次 | bre+ad | 可匹配范围从bread到bre…ad |
| * | 匹配*前面的字符零次或多次 | ro*se | 可匹配范围从rse到ro…se |
| {n} | 匹配{}前面的字符n次 | hit{2}er | 只能匹配hitter |
| {n,} | 匹配{}前面的字符最少n次 | hit{2,}er | 可匹配范围从hitter到hitt…er |
用户名验证的案例:
如果用户名输入合法(6~16位的用户名只能是),则提示信息为:用户名合法,颜色为绿色;如果用户名输入不合法,则提示信息为:用户名不合法,并且颜色为绿色。
代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="../js/jquery.js"></script>
</head>
<style>
.success{
color: green;
}
.wrong{
color: red;
}
</style>
<body>
<label>
用户名:
<input type="text" class="uname"><span></span>
</label>
<script>
$(function(){
var reg = /^[a-zA-z0-9_-]{6,16}$/
$('.uname').bind('blur',function(){
let str = $(this).val()
if(reg.test(str)){
if($('span').hasClass('wrong')){
$('span').removeClass('wrong');
}
$('span').html('输入格式正确');
$('span').addClass('success');
}else{
$('span').html('输入格式不正确');
$('span').addClass('wrong');
}
})
})
</script>
</body>
</html>效果如下:

5.预定义类
| 字符 | 说明 |
| . | 匹配除“\n”外的任何单个字符 |
| \d | 匹配所有0~9之间的任意一个数字,相当于[0-9] |
| \D | 匹配所有0~9以外的字符,相当于[^0-9] |
| \w | 匹配任意的字母、数字和下划线,相当于[a-zA-Z0-9] |
| \W | 除所有字母、数字和下划线以外的字符,相当于[^a-zA-Z0-9] |
| \s | 匹配空格(包括换行符、制表符、空格符等),相当于[\t\r\n\v\f] |
| \S | 匹配非空格的字符,相当于[^\t\r\n\v\f] |
| \b | 匹配单词分界符。如“\bg”可以匹配“best grade”,结果为“g” |
| \f | 匹配一个换页符(form-feed) |
| \B | 非单词分界符。如“\Bade”可以匹配“best grade”,结果为“ade” |
| \t | 匹配一个水平制表符(tab) |
| \n | 匹配一个换行符(linefeed) |
| \xhh | 匹配ISO-8859-1值为hh(2个16进制数字)的字符,如“\x61”表示“a” |
| \r | 匹配一个回车符(carriage return) |
| \v | 匹配一个垂直制表符(vertical tab) |
| \uhhhh | 匹配Unicode 值为 hhhh (4个16进制数字)的字符,如“\u597d”表示“好” |
三、String类中的方法
1.match()方法;
match()方法:根据正则匹配出所有符合要求的内容匹配成功后将其保存到数组中,匹配失败则返回false。
var str = "It's is the shorthand of it is";
var reg1 = /it/gi;
str.match(reg1); // 匹配结果:(2) ["It", "it"]
var reg2 = /^it/gi;
str.match(reg2); // 匹配结果:["It"]
var reg3 = /s/gi;
str.match(reg3); // 匹配结果:(4) ["s", "s", "s", "s"]
var reg4 = /s$/gi;
str.match(reg4); // 匹配结果:["s"]
2.search()方法
search()方法可以返回指定模式的子串在字符串首次出现的位置,相对于indexOf()方法来说功能更强大。
var str = '123*abc.456';
console.log(str.search('.*')); // 输出结果:0
console.log(str.search(/[\.\*]/)); // 输出结果:3
3、split()方法
split()方法:split()方法用于根据指定的分隔符将一个字符串分割成字符串数组,其分割后的字符串数组中不包括分隔符。
例如:
按照字符串中的“@”和“.”两种分隔符进行分割。
var str = 'test@123.com';
var reg = /[@\.]/;
var split_res = str.split(reg);
console.log(split_res); // 输出结果:(3) ["test", "123", "com"]
4、replace()方法
replace()方法用于替换字符串,用来操作的参数可以是一个字符串或正则表达式。
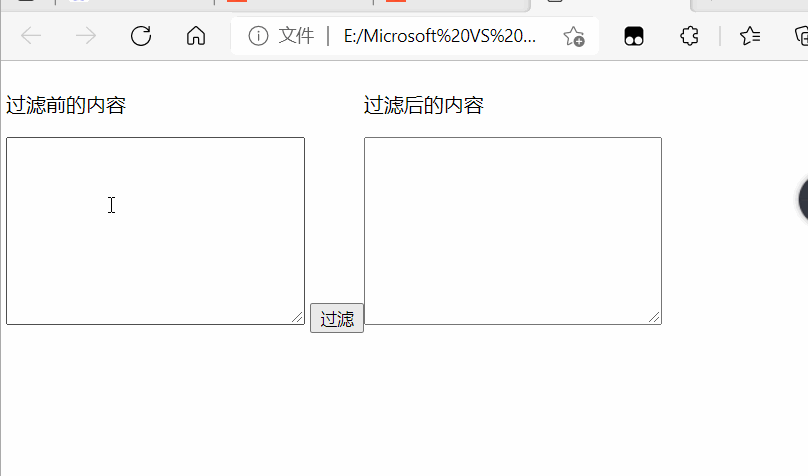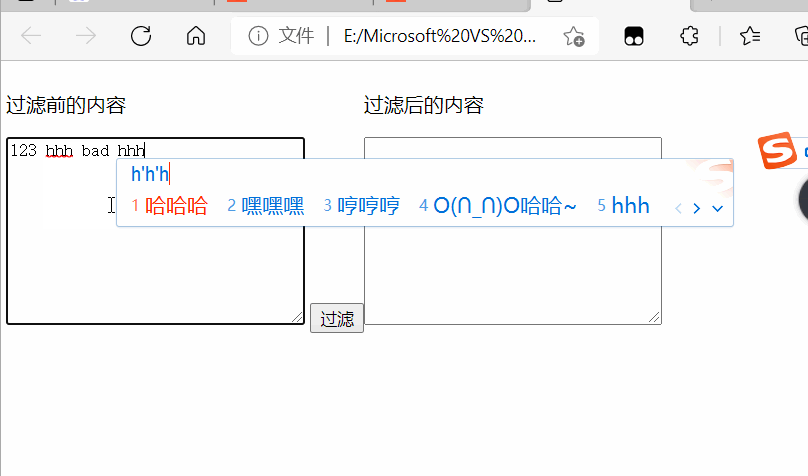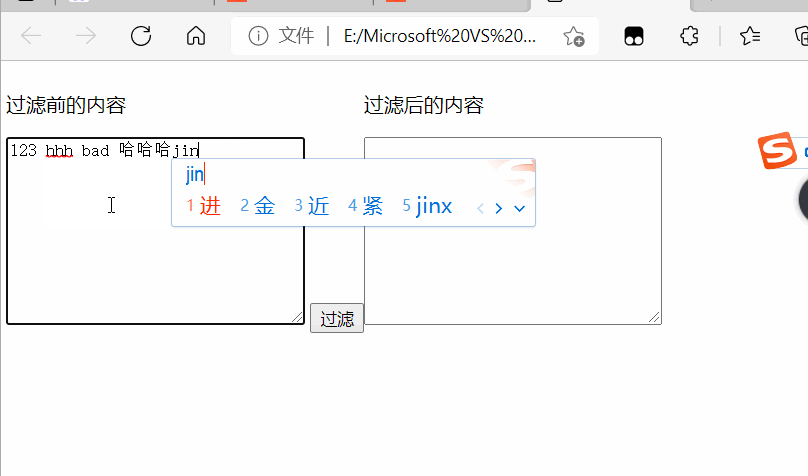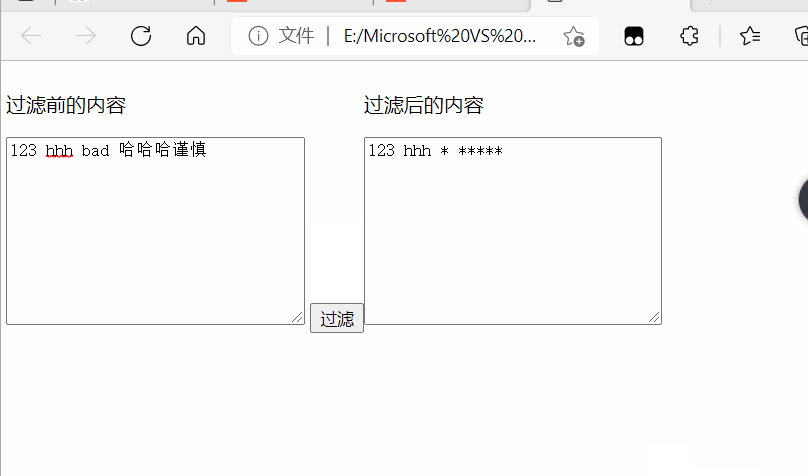
例如:写一个查找并替换敏感词的案例(过滤汉字和‘bad’这个单词):
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body style="display:flex">
<div>
<p>过滤前的内容</p>
<textarea name="" id="" cols="30" rows="10"></textarea>
<button id = 'btn'>过滤</button>
</div>
<div>
<p>过滤后的内容</p>
<textarea name="" id="" cols="30" rows="10"></textarea>
</div>
<script>
var text = document.querySelectorAll('textarea');
console.log(text);
var btn = document.querySelector('button');
btn.onclick = function() {
text[1].value = text[0].value.replace(/(bad)|[\u4e00-\u9fa5]/gi, '*');
}
</script>
</body>
</html>
运行效果为: