
字符编码的原理及发展(一):
之前说到计算机中的任何数据都是以二进制数的形式存在的,可是我们对于这些数据如果只是以二进制数来显示的话,这满屏的0和1我也看不懂啊!(其实可以理解为计算机只认识比特<0和1>,人只认识字符,之间需要一个工具将0和1转换为我们认识的字符)
对于这个问题,字符集编码就由此诞生了,要了解字符集编码那首先得了解它的历史,最早的字符集编码是美国的ASCII(美国信息交换标准代码)码,ASCII码所有符号均由一个字节8bit组成,也就是ASCII最多能表示2⁸=256个字符。但是英文字母也不过只有26个,再加上一些其他字符,也用不着256个呀?所以ASCII采用后七位(2⁷=128)来表示字符,也就是
0××× ××××
(ASCII值对应从0000 0000开始所要相加的数值,例如+1:0000 0001 +2:0000 0010 +3:0000 0011以二进制的加法以此类推)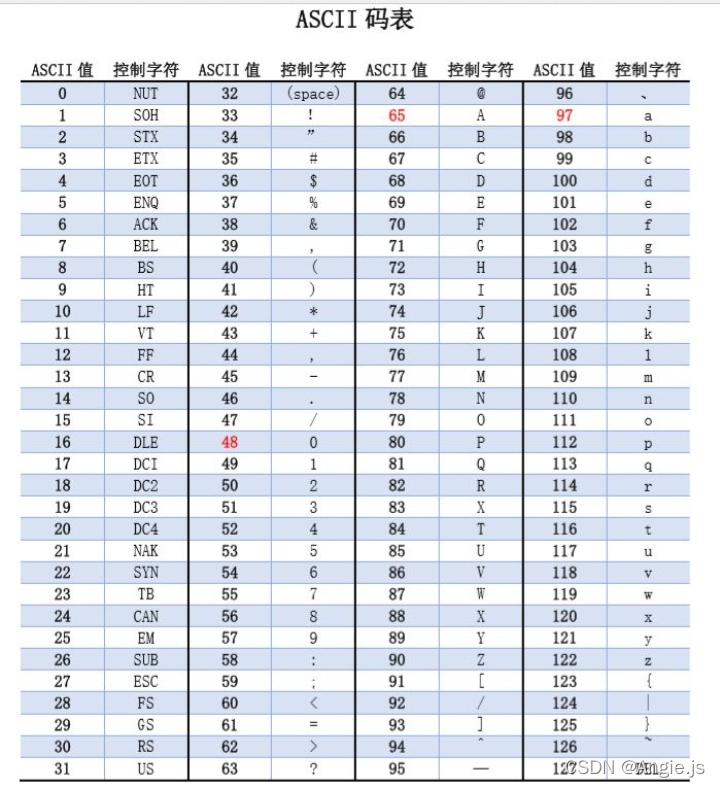
那前一位有什么作用呢?后面再说。
ASCII的出现就解决计算机的编码问题。之后ASCII编码方式逐渐被各个国家采用,但是有的国家并不使用英文呀?那咋办?那就修改要编码的字符呗,所以ASCII就衍生出了各个国家的不同版本,但是ASCII如果还是按照英文的128位那也行不通,例如法国除了字母还得标注音符,这128位哪里够用?得了,那就256位吧,这样一来欧美很多国家普遍使用的是一个全字节进行编码
随后ASCII进入我国后,问题也就来了,中华文化博大精深,单汉字就有数十万个,常用字也有六七千,这尼玛256个塞牙缝都不够,行,一个字节不行是吧,那就来两个,2¹⁶=65536位,这下行了吧!可能又有人要说了,哥,咱们数十万汉字这也还是不够啊?够,怎么不够,我们只需要纳入常用字就行了,因为常用字就已经占到了我们日常生活中所用到的99.7%的汉字。
如此一来也就解决了汉字的编码问题。这也就是1980年中国国家标准总局发布的《信息交换用汉字编码字符集》,代号:GB 2312。
GB 2312共收录常用汉字6763个、拉丁字母、希腊字母、日文俄文部分字符,还有一些特殊符号。不过随着国际信息交流越来越频繁,而各个国家又使用着各自不同的字符集编码,乱码的事情时有发生。曾经还出现俄国人发封文件到中国,因为俄国和中国使用的字符集编码不同,结果中国人看到的却是一堆乱码,那这样的问题又如何解决呢?
下次再探讨国际字符编码方式的统一及Unicode
编码的诞生
作者水平有限,有错误还望批评指正