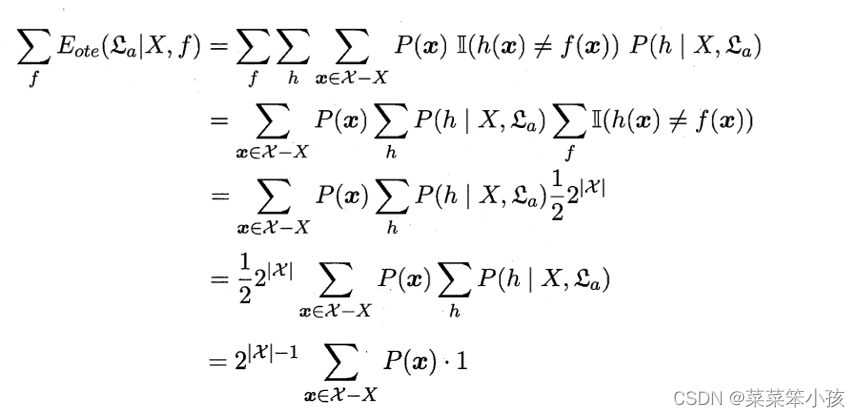目录
一、机器学习概述
1.1 什么是机器学习?
1.2 为什么需要机器学习?
1.3 机器学习应用场景
1.4 机器学习的一般流程
1.5 典型的机器学习过程
二、机器学习的基本术语
三.假设空间与版本空间
四、归纳偏好
1.哪种更好
2.没有免费的午餐(No Free Lunch Theorem)
一、机器学习概述
基本概念:从具体到抽象
1.1 什么是机器学习?
机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测
目前被广泛采用的机器学习的定义是“利用经验来改善计算机系统自身的性能”。
1.2 为什么需要机器学习?
解放生产力,智能客服,可以不知疲倦的24小时作业
解决专业问题,ET医疗,帮助看病
提供社会便利,例如杭州的城市大脑
1.3 机器学习应用场景
自然语言处理
无人驾驶
计算机视觉
推荐系统
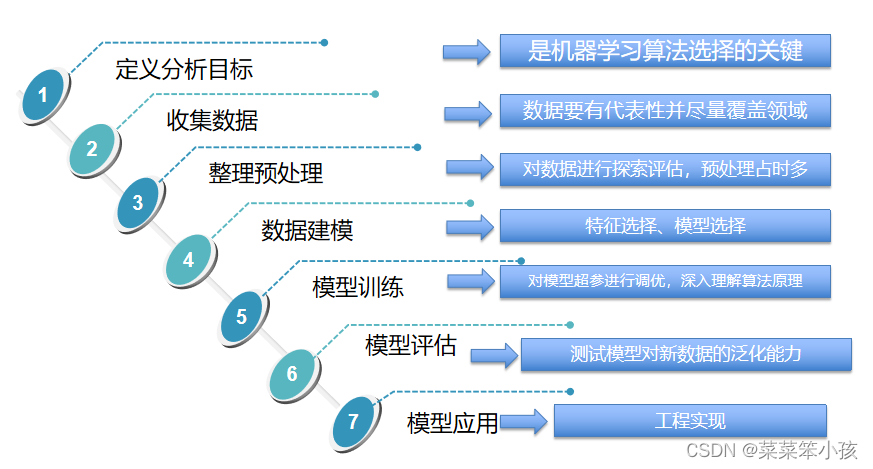
1.4 机器学习的一般流程
1.5 典型的机器学习过程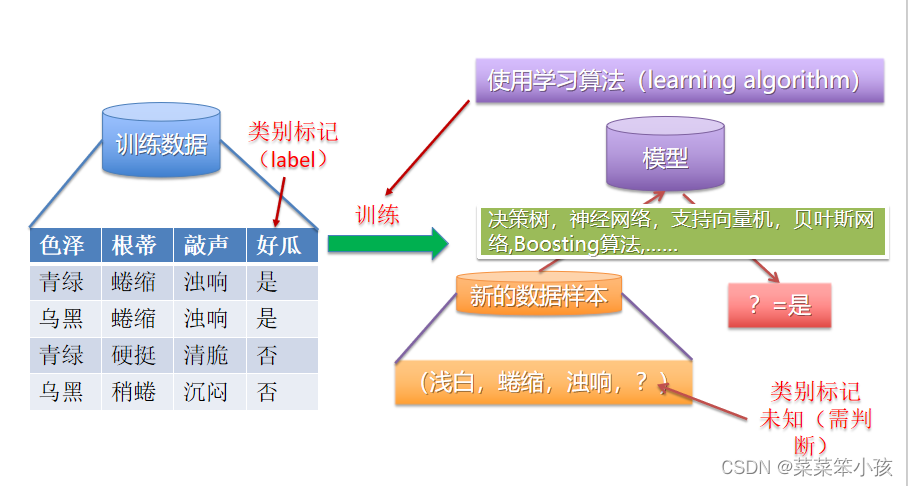
二、机器学习的基本术语
数据集:所有记录的集合
实例(instance)或样本(example):每一条记录
特征(feature)或属性(attribute):单个的特点,一个记录构成一个特征向量,可用坐标轴上的一个点表示
属性值(attribute value):
- 属性上的取值,例如“青绿”“乌黑”
- 属性张成的空间称为 “属性空间”(attribute space)、“ 样本空间”(sample space)或“输入空间”.
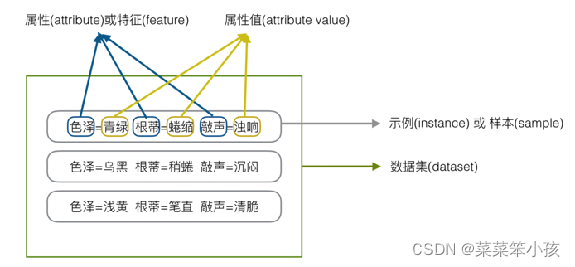
特征空间(feature space):
- 分别以每个特征作为一个坐标轴,所有特征所在坐标轴张成一个用于描述不同样本的空间,称为特征空间
- 在该空间中,每个具体样本就对应空间的一个点,在这个意义下,也称样本为样本点。
- 每个样本点对应特征空间的一个向量,称为 “特征向量”
- 特征的数目即为特征空间的维数。
维数:一个样本的特征数,维数灾难
训练集(trainning set),[特殊]:所有训练样本的集合
测试集(test set),[一般]:所有测试样本的集合
泛化能力(generalization),即从特殊到一般:机器学习出来的模型适用于新样本的能力
标记(label):
- 有前面的样本数据显然是不够的,要建立这样的关于“预测”(prediction) 的模型,我们需获得训练样本的“结果”信息,例如“((色泽=青绿;根蒂=蜷缩;敲声= =浊响),好瓜)”.这里关于示例结果的信息,例如“好瓜”,称为“标记”(label); 拥有了标记信息的示例,则称为“样例”(example).
分类(classification):
- 若我们欲预测的是离散值,例如“好瓜”“坏瓜”,此类学习任务称为"分类"
回归(regression)
- 若欲预测的是连续值,例如西瓜成熟度0.95、0.37,类学习任务称为“回归”.
- 对只涉及两个类别的称为“二分类’(binary classification)’
聚类”(clustering)
- 即将训练集中的样本分成若干组,每组称为一个 “簇”(cluster);
根据训练数据是否拥有标记信息,学习任务可大致划分为两大类:“ 监督学习”(supervised learning) 和 “无监督学习”(unsupervised learning), 分类和回归是前者的代表,而聚类则是后者的代表.
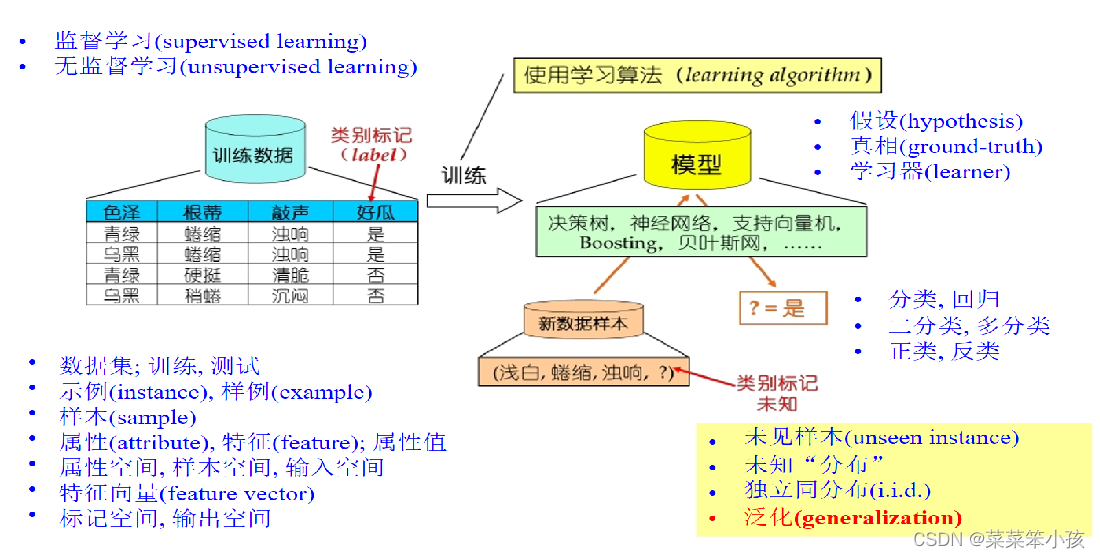
三.假设空间与版本空间
假设(hypothesis)、假设空间(hypothesis space):
- 每一个具体的模型就是一个“假设(hypothesis)”
- 模型的学习过程就是一个在所有假设构成的假设空间进行搜索的过程,搜索的目标就是找到与训练集“匹配(fit)”的假设。
广义归纳学习:从样例中学习
狭义归纳学习:从训练数据中学得概念,因此也称为“概念学习”或“概念形成”。其中最基本的是“布尔概念学习”

在这里你是否会有好多好多小问号??????
下面是:可能取值所形成的假设组成假设空间

而我们就是要通过一定的方法来确定所谓的 “ ?” !!!那就是学习和搜索
学习过程:在所有假设组成的空间中进行搜索的过程。
搜索目标:找到与训练集“匹配”的假设,即能够将训练集中的瓜判断正确的假设。
特殊情况: 某个因素可取任意值,用*来表示;目标概念根本不存在,用∅来表示这个假设
设每个因素的取值分别为m1,m2,m3,…,mk,则假设空间规模为: ∏(mi+1)+1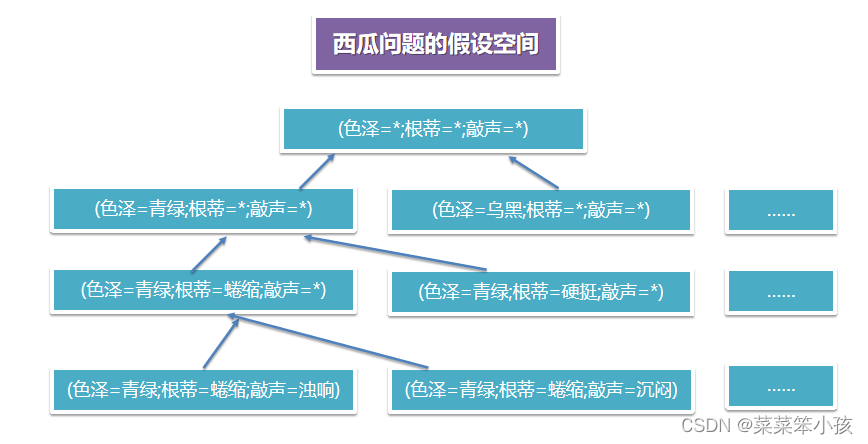
然后,我们只需在假设空间的搜索过程中,不断删除与正例不一致的假设和、或与反例一致的假设,最终将会获得与训练集一致(即对所有训练样本能够进行正确判断)的假设
版本空间(version space)
- 基于有限规模的训练样本集进行假设的匹配搜索,会存在多个假设与训练集一致的情况,称这些假设组成的集合为“版本空间”

四、归纳偏好
1.哪种更好
机器学习算法在学习过程中对某种类型假设的偏好:
如图是A更好还是B更好?????
一般原则:奥卡姆剃刀又称为吝啬定律(Law of parsimony),或者称为朴素原则。(是一种常用的、自然科学研究中最基本的原则,即“若有多个假设与观察一致,则选最简单的那个”)
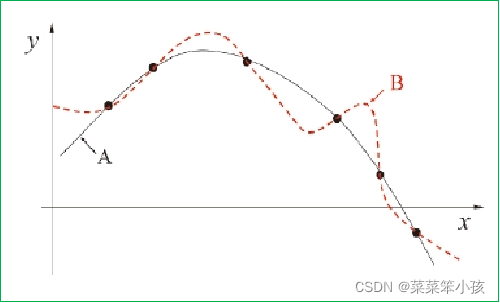
2.没有免费的午餐(No Free Lunch Theorem)
NFL定理:一个算法ℒa若在某些问题上比另一个算法ℒb好,必存在另一些问题, ℒb比ℒa好
NFL定义有一个重要前提:所有“问题”出现的机会相同、或所有问题同等重要。实际情形并非如此;我们通常只关注自己正在试图解决的问题。脱离具体问题,空泛地谈论“什么学习算法更好”,毫无意义!
简单起见,假设样本空间χ和假设空间Η都是离散的。令P(ℎ│X,ℒa)代表算法ℒa基于训练数据X产生假设ℎ的概率。令f代表希望学习的真实目标函数。则ℒa在训练集之外所有样本上的总误差为:
![]()
考虑二分类问题,目标函数可以为任何函数χ⟼{0,1},函数空间为{0,1}^|χ|,对所有可能的f按均匀分布对误差求和,有:
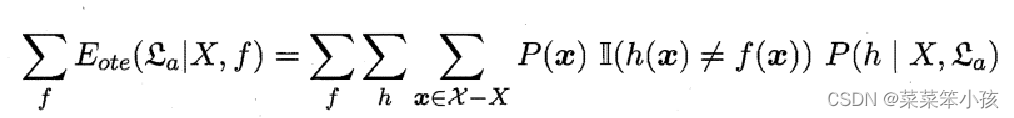
总误差与学习算法无关,所有算法一样好!