前言
利用Python爬取QQ音乐评论。废话不多说。
让我们愉快地开始吧~
开发工具
Python版本: 3.6.4
相关模块:
requests模块;
re模块;
pymysql模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
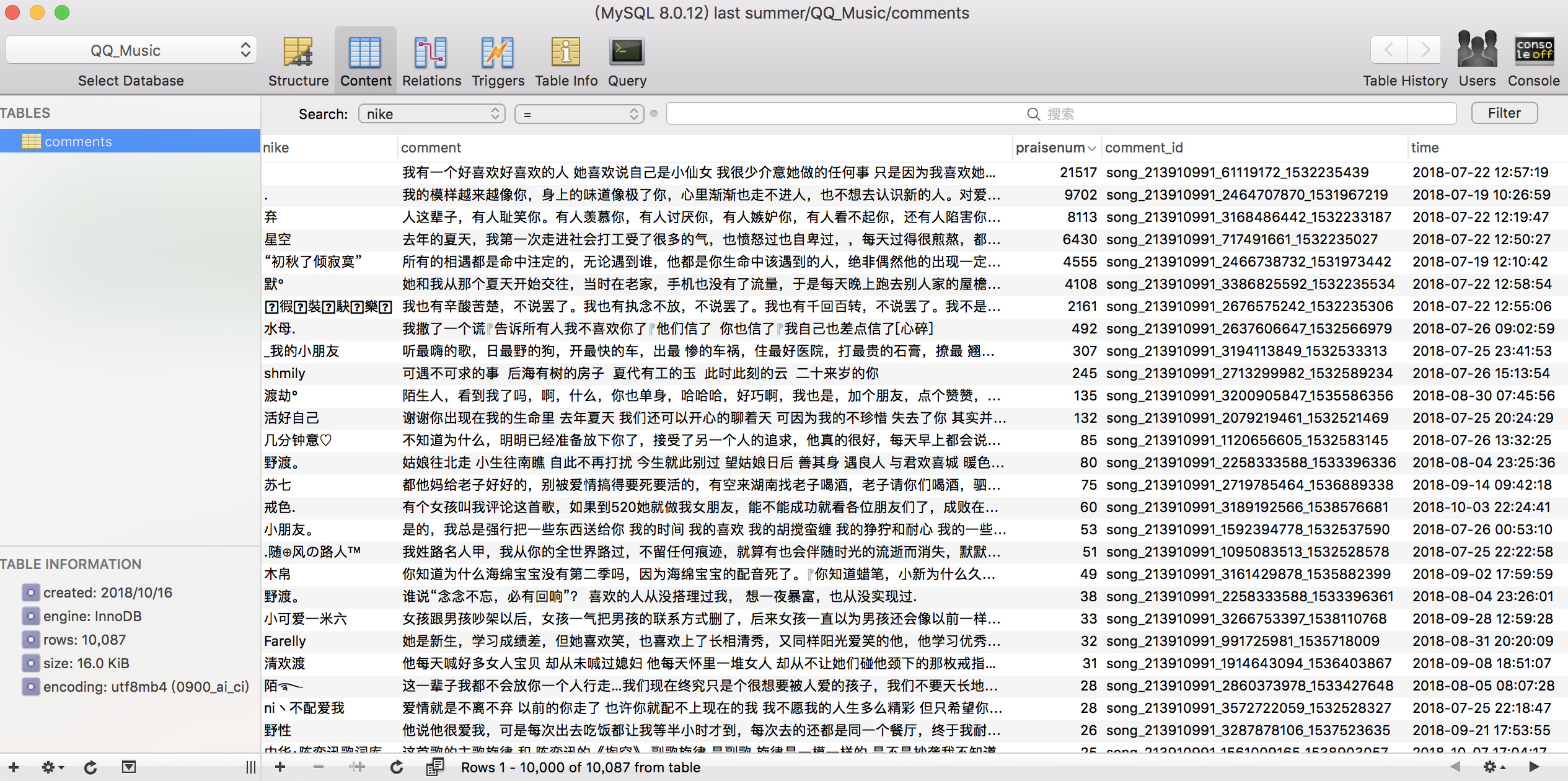
通过这次爬取,学习了数据库MySQL,因为之前都是在windows上操作,而这回需要在Mac上操作,所以就在Mac上安装了MySQL以及MySQL的管理工具Sequel Pro,最后也是安装成功,数据库连接也没有问题。
接下来创建数据库,表格及主键信息。
import pymysql
# 创建数据库
db = pymysql.connect(host='127.0.0.1', user='root', password='774110919', port=3306)
cursor = db.cursor()
cursor.execute("CREATE DATABASE QQ_Music DEFAULT CHARACTER SET utf8mb4")
db.close()
import pymysql
# 创建表格, 设置主键
db = pymysql.connect(host='127.0.0.1', user='root', password='774110919', port=3306, db='QQ_Music')
cursor = db.cursor()
sql = 'CREATE TABLE IF NOT EXISTS comments (nike VARCHAR(255) NOT NULL, comment VARCHAR(255) NOT NULL, praisenum INT NOT NULL, comment_id VARCHAR(255) NOT NULL, time VARCHAR(255) NOT NULL, PRIMARY KEY (comment))'
cursor.execute(sql)
db.close()
针对QQ音乐中去年夏天的网页进行分析,查看了所有评论的尾页,发现时间缩水了,因为热评中有一条评论的时间7月12号,而所有评论最后一页的时间却是7月16号。很明显,所有评论并不是货真价实的所有评论,不知这算不算QQ音乐的BUG。
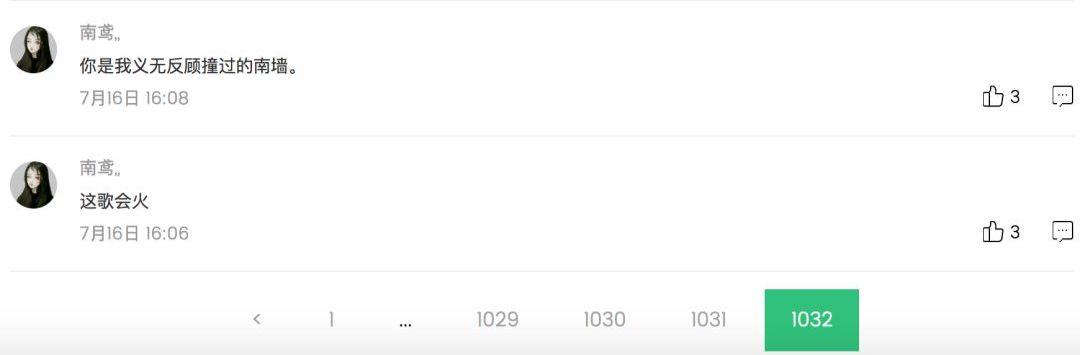
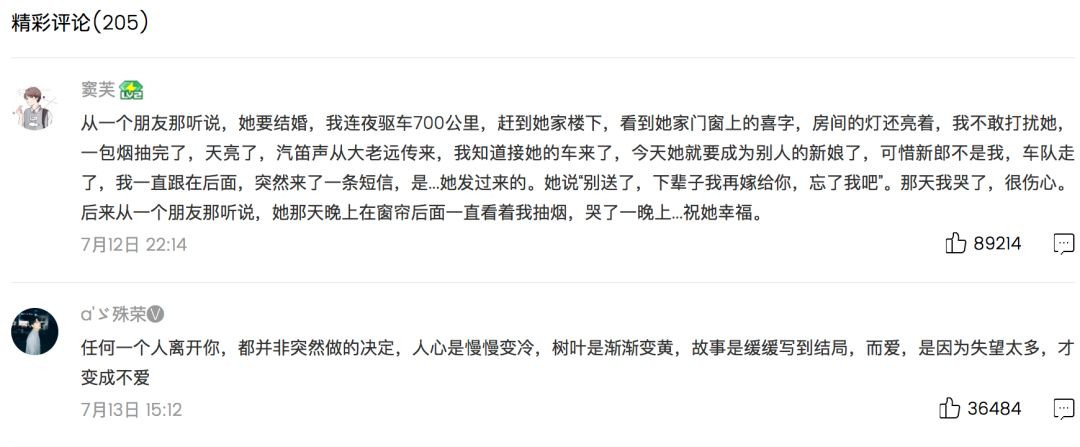
还有一个就是直接点击最后一页的时候,并不能直接返回真正的信息,需要从最后一页往前翻,到了真正的信息页时,然后再往后翻,才能得到最后一页的真正信息。
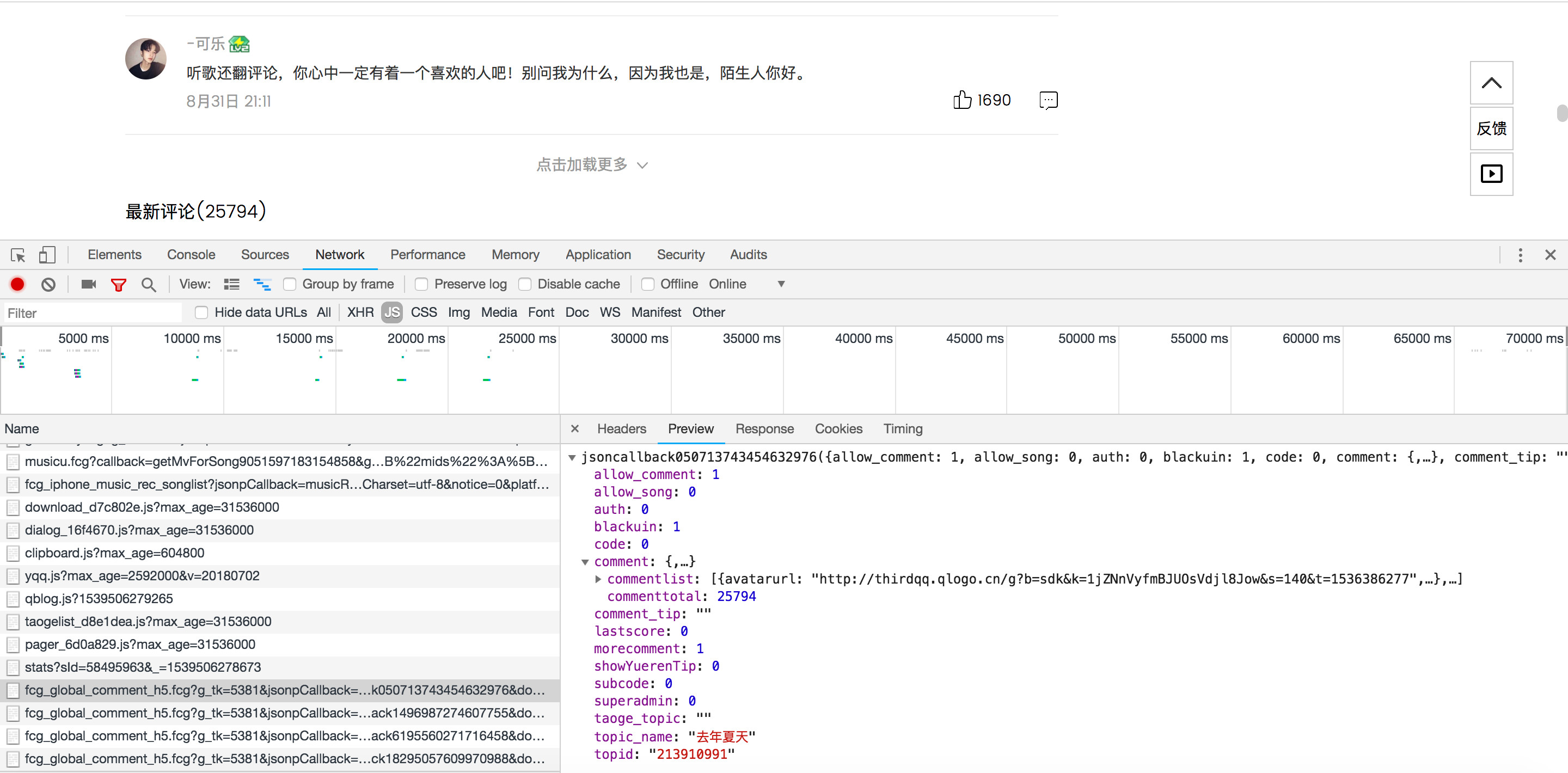
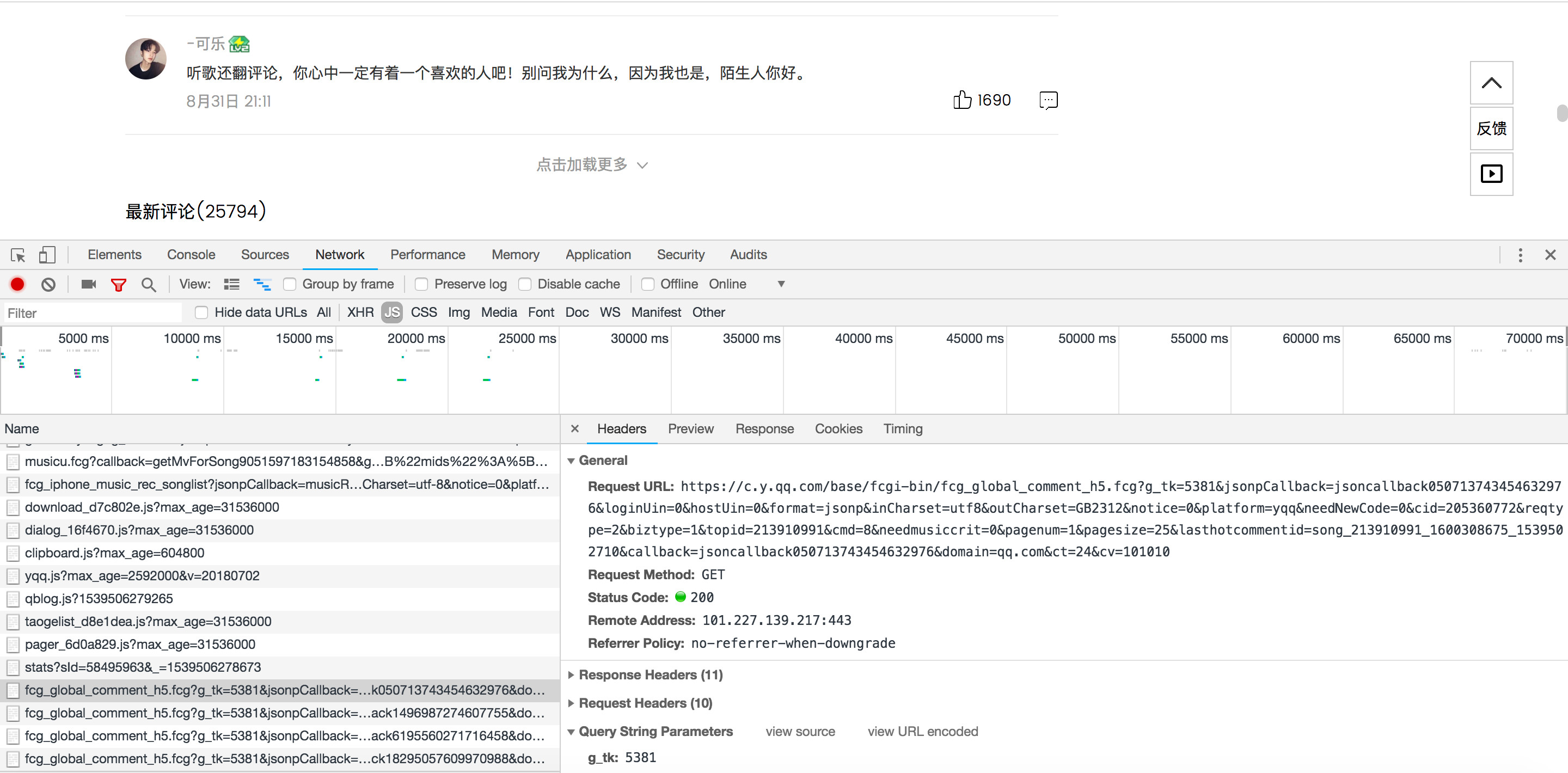
同样是Ajax请求,确认网址后,分析一下请求头,发现主要是三个参数发生变化:jsoncallback
pagenum
lasthotcommentid
pagenum不难理解,就是页数。jsoncallback经过实验后,发现并不会影响请求,所以设置时无需改动,lasthotcommentid的值对应的是上一页最后一个评论者的ID,所以需要随时改动。
即改变pagenum,lasthotcommentid的值,就可成功实现请求。
部分代码
import re
import json
import time
import pymysql
import requests
URL = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?'
HEADERS = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
PARAMS = {
'g_tk': '5381',
'jsonpCallback': 'jsoncallback4823183319594757',
'loginUin': '0',
'hostUin': '0',
'format': 'jsonp',
'inCharset': 'utf8',
'outCharset': 'GB2312',
'notice': '0',
'platform': 'yqq',
'needNewCode': '0',
'cid': '205360772',
'reqtype': '2',
'biztype': '1',
'topid': '213910991',
'cmd': '8',
'needmusiccrit': '0',
'pagenum': '0',
'pagesize': '25',
'lasthotcommentid': '',
'callback': 'jsoncallback4823183319594757',
'domain': 'qq.com',
'ct': '24',
'cv': '101010',
}
LAST_COMMENT_ID = ''
db = pymysql.connect(host='127.0.0.1', user='root', password='774110919', port=3306, db='QQ_Music', charset='utf8mb4')
cursor = db.cursor()
def get_html(url, headers, params=None, tries=3):
try:
response = requests.get(url=url, headers=headers, params=params)
response.raise_for_status()
response.encoding = 'utf-8'
except requests.HTTPError:
print("connect failed")
if tries > 0:
print("reconnect...")
last_url = url
get_html(last_url, headers, tries-1)
else:
print("3 times failure")
return None
return response
def paras_html(html):
data = {}
content = json.loads(html[29:-3])
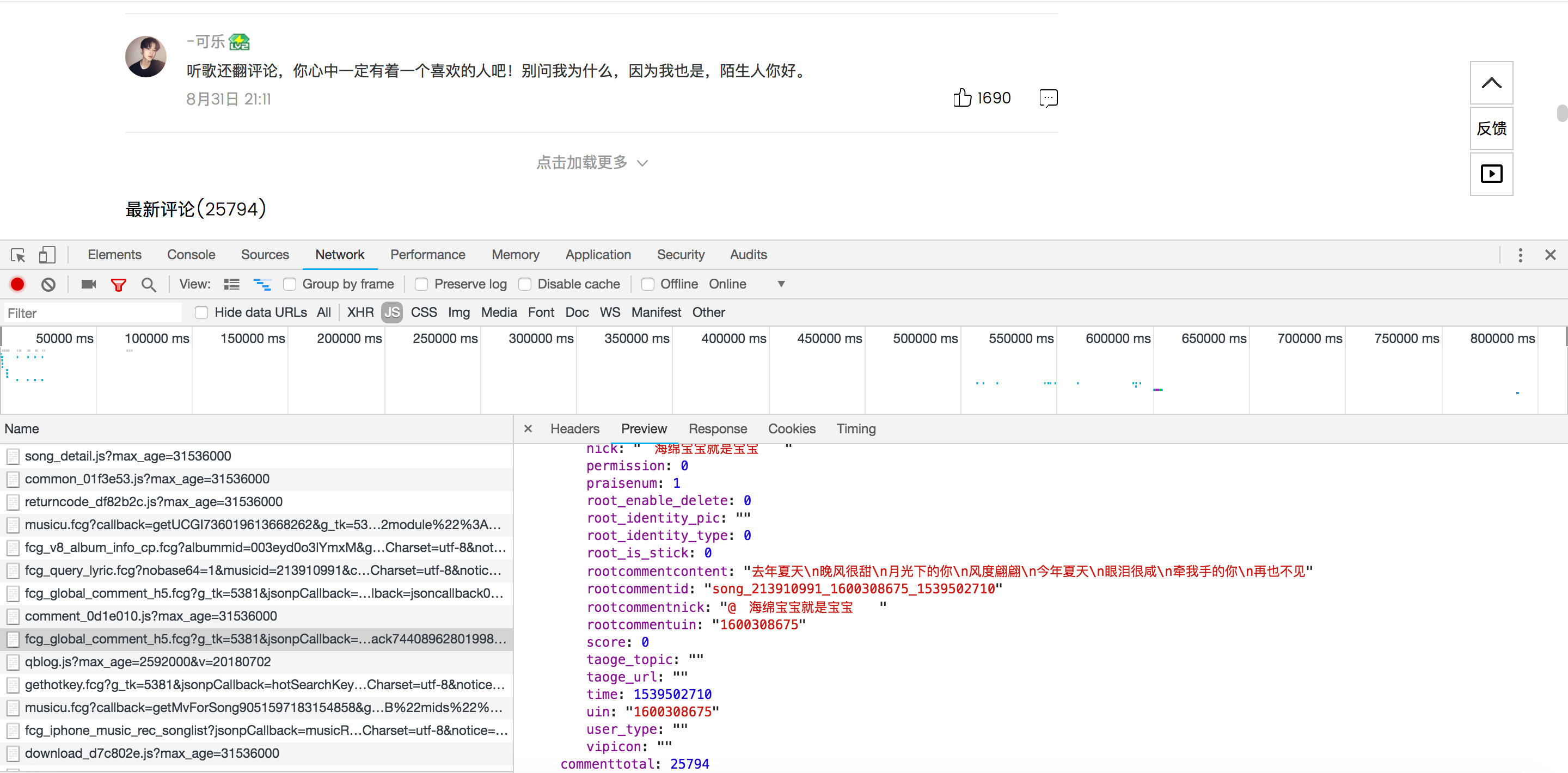
for item in content['comment']['commentlist']:
data["nike"] = item.get("nick")
data["comment"] = re.sub(r"\\n", " ", item.get("rootcommentcontent"))
data["comment"] = (re.sub(r"\n", " ", data["comment"]))[0:255]
data["praisenum"] = item.get("praisenum")
data["comment_id"] = item.get("commentid")
data["time"] = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(item.get("time"))))
yield data
def to_mysql(data):
table = 'comments'
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE'.format(table=table, keys=keys, values=values)
update = ','.join([" {key} = %s".format(key=key) for key in data])
sql += update
try:
if cursor.execute(sql, tuple(data.values())*2):
print('Successful')
except:
print('Failed')
db.rollback()
db.commit()
if __name__ == '__main__':
main()
最后成功获取评论信息