
SQL概述
3.1.什么是sql?
- SQL:Structure Query Language。(结构化查询语言),通过sql操作数据库(操作数据库,操作表,操作数据)
3.2sql的语法
- 每条语句以分号结尾(命令行里面需要),如果在navicat,java代码中不是必须加的。
- SQL在window中不区分大小写,关键字中认为大写和小写是一样的
3.3sql的分类
- Data Definition Language (DDL数据定义语言) 如:操作数据库,操作表
- Data Manipulation Language(DML数据操纵语言),如:对表中的记录操作增删改
- Data Query Language(DQL 数据查询语言),如:对表中的记录查询操作
- Data Control Language(DCL 数据控制语言),如:对用户权限的设置
库DDL
3.1创建数据库
- 语法
create database 数据库名 [character set 字符集][collate 校对规则] 注: []意思是可选的意思
字符集(charset):是一套符号和编码。
- 练习
创建一个day16的数据库(默认字符集)
create database web14_1;
创建一个day16_2的数据库,指定字符集为gbk(了解)
create database web14_2 character set gbk;
3.2查看所有的数据库
3.2.1查看所有的数据库
- 语法
show databases;
3.2.2查看数据库的定义结构【了解】
- 语法
show create database 数据库名;
- 查看web14_1这个数据库的定义
show create database web14_1;
3.3删除数据库
- 语法
drop database 数据库名;
- 删除web14_2数据库
drop database web14_2;
3.4修改数据库【了解】
- 语法
alter database 数据库名 character set 字符集;
- 修改web14_1这个数据库的字符集(gbk)
alter database web14_1 character set gbk;
- 查看所有字符集
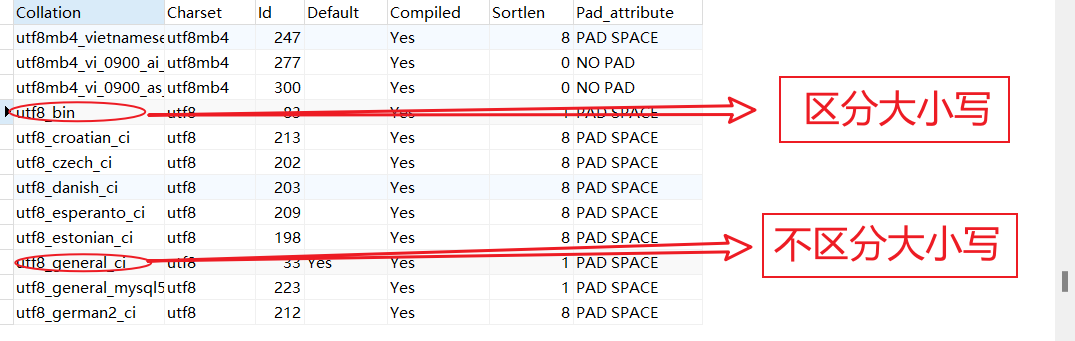
注意:
- 是utf8,不是utf-8
- 不是修改数据库名
3.5其他操作
- 切换数据库, 选定哪一个数据库
use 数据库名; //注意: 在创建表之前一定要指定数据库. use 数据库名
- 练习: 使用web14_1
use web14_1;
- 查看正在使用的数据库
select database();
表DDL
定义表
3.1语法
create table 表名(
字段名 字段类型 [约束],
字段名 字段类型 [约束],
........
字段名 字段类型 [约束]
);
3.2 类型
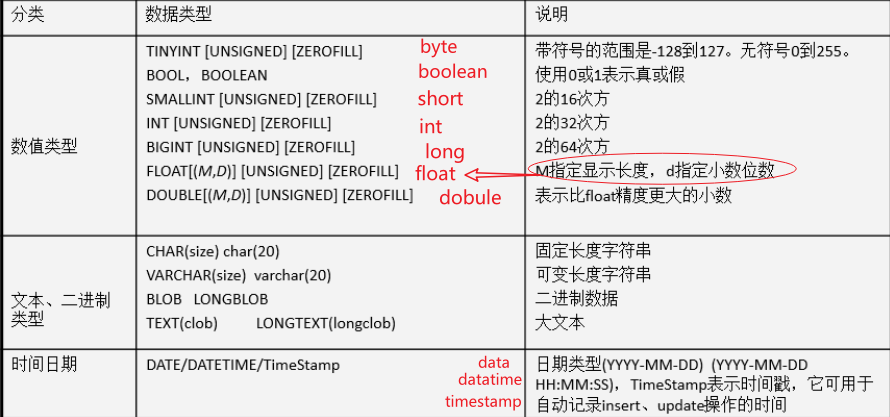
-
整型 一般使用int 或者bigint
-
浮点/双精度型
- 默认的范围 float或者double
- 指定范围 float(M,D) eg: float(4,2) 表达的范围: -99.99~99.99
-
字符
- 固定长度 char(n) eg: char(20), 最大能存放20个字符. ‘aaa’, 还是占20个字符的空间
- 可变长度 varchar(n) eg:varchar(20), 最大能存放20个字符. ‘aaa’, 占3个字符的空间
一般使用varchar(n) 节省空间; 如果长度(eg:身份证)是固定的话 可以使用char(n) 性能高一点
-
关于大文件
- 一般在数据库里面很少存文件的内容, 一般存文件的路径
- 一般不使用二进制存, 使用varchar(n)存文件的路径
-
日期
- DATE 只有日期
- DATETIME 日期和时间
3.3 约束
- 即规则,规矩 限制;
- 作用:保证用户插入的数据保存到数据库中是符合规范的
| 约束 | 约束关键字 |
|---|---|
| 主键 | primary key |
| 唯一 | unique |
| 非空 | not null |
约束种类:
-
not null: 非空 ; eg: username varchar(40) not null username这个字段不能为空,必须要有数据
-
unique:唯一约束, 后面的数据不能和前面重复; eg: cardNo char(18) unique; cardNo字段不能出现重复的数据
-
primary key;主键约束(非空+唯一); 一般用在表的id列上面. 一张表基本上都有id列的, id列作为唯一标识的
- auto_increment: 自动增长,必须是设置了primary key之后,才可以使用auto_increment
-
id int primary key auto_increment; id不需要我们自己维护了, 插入数据的时候直接插入null, 自动的增长进行填充进去, 避免重复了.
注意:
- 先设置了primary key 再能设置auto_increment
- 只有当设置了auto_increment 才可以插入null 自己维护 否则插入null会报错
id列:
- 给id设置为int类型, 添加主键约束, 自动增长
- 或者给id设置为字符串类型,添加主键约束, 不能设置自动增长
3.4练习
- 创建一张学生表(含有id字段,姓名字段,性别字段. id为主键自动增长)
create table student(
id int primary key auto_increment,
name varchar(40),
sex int
);
查看表
3.1查看所有的表
show tables;
3.2查看表的定义结构
-
语法
desc 表名; -
练习: 查看student表的定义结构
desc student;
修改表
3.1语法
增加一列;
alter table 表 add 字段 类型 约束;
修改列的类型约束;
-
alter table 表 modify 字段 类型 约束 ;
修改列的名称,类型,约束;
-
alter table 表 change 旧列 新列 类型 约束;
删除一列;
-
alter table 表名 drop 列名;
修改表名 ;
-
ename table 旧表名 to 新表名;
3.2练习
增加:
- 给学生表增加一个grade字段
alter table student add grade varchar(20) not null;
修改字段数据类型:
- 给学生表的sex字段改成字符串类型
alter table student modify sex varchar(10);
修改字段为另一个字段:
- 给学生表的grade字段修改成class字段
alter table student change grade class varchar(20);
删除字段:
- 把class字段删除
alter table student drop class;
修改表名:
- 把学生表修改成老师表(了解)
rename table student to teacher
知识点-删除表【掌握】
1.讲解
-
语法
drop table 表名; -
把teacher表删除
drop table teacher;
数据增删改
- 准备工作: 创建一张商品表(商品id,商品名称,商品价格,商品数量.)
create table product(
pid int primary key auto_increment, //只有设置了auto_increment id列才可以赋值为null
pname varchar(40),
price double,
num int
);
数据插入:
方式一:
-
插入指定列, 如果没有把这个列进行列出来, 以null进行自动赋值了.
eg: 只想插入pname, price , insert into product(pname, price) values(‘mac’,18000);
insert into 表(列,列..) values(值,值..);
注意: 如果没有插入了列设置了非空约束, 会报错的
方式二:
-
插入所有的列
insert into 表 values(值,值…);
eg:
insert into product values(null,‘苹果电脑’,18000.0,10);
insert into product values(null,‘华为5G手机’,30000,20);
insert into product values(null,‘小米手机’,1800,30);
insert into product values(null,‘iPhonex’,8000,10);
insert into product values(null,‘苹果电脑’,8000,100);
insert into product values(null,‘iPhone7’,6000,200);
insert into product values(null,‘iPhone6s’,4000,1000);
insert into product values(null,‘iPhone6’,3500,100);
insert into product values(null,‘iPhone5s’,3000,100);insert into product values(null,‘方便面’,4.5,1000);
insert into product values(null,‘咖啡’,11,200);
insert into product values(null,‘矿泉水’,3,500);
命令行插入中文数据报错:
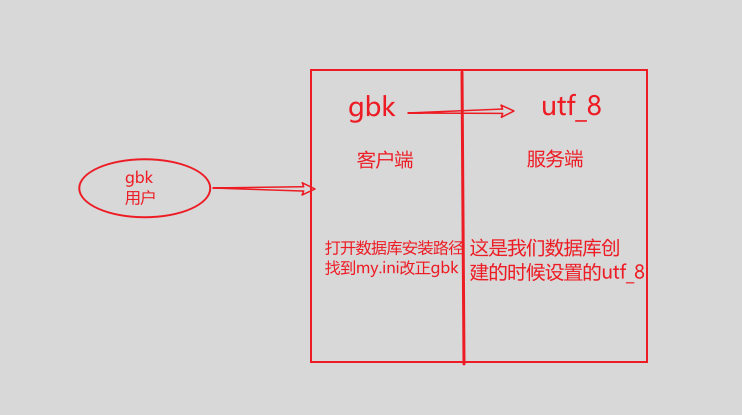
-
关闭服务, net stop MySql
-
重新打开命令行,开启服务, net start MySql
注意:不只是字符串需要用引号引起来,日期也需要引起来
数据更新
3.1语法
update 表 set 列 =值, 列 =值 [where 条件]
3.2练习
- 将所有商品的价格修改为5000元
- 将商品名是Mac的价格修改为18000元
- 将商品名是Mac的价格修改为17000,数量修改为5
- 将商品名是方便面的商品的价格在原有基础上增加2元
update product set price = 5000;
UPDATE product set price = 18000 WHERE name = 'Mac';
UPDATE product set price = 17000,num = 5 WHERE name = 'Mac';
UPDATE product set price = price+2 WHERE name = '方便面';
注意:
- 如果没有加where 更新整个的
- 工作里面一般是加where
数据删除
1delete
- 语法
delete from 表 [where 条件] 注意: 删除数据用delete,不用truncate
-
练习
- 删除表中名称为’Mac’的记录
- 删除价格小于5001的商品记录
- 删除表中的所有记录
delete from product where pname = 'Mac';
delete from product where price < 5001;
delete from product;
2truncate
truncate table 表;
小结
- 删除记录
delete from 表 【where 条件】
truncate table 表;
-
delete 和truncate区别【面试题】
- DELETE 删除表中的数据,表结构还在; 删除的记录可以找回
- TRUNCATE 删除是把表直接DROP掉,然后再创建一个同样的新表(空)。删除的记录不可以找回
-
工作里面的删除
- 物理删除: 真正的删除了, 数据不在, 使用delete就属于物理删除
- 逻辑删除: 没有真正的删除, 数据还在. 搞一个标记, 其实逻辑删除是更新 eg: state字段 1 启用 0禁用
工作里面一般使用逻辑删除用的多
数据查
1基本查询语法
select [*][列名 ,列名][列名 as 别名 ...] [distinct 字段] from 表名 [where 条件]
2简单查询
2.1 查所有记录
- 语法
select * form 表
- 查询商品表里面的所有的列
select * from product;
2.2查询某张表特定列的记录
- 语法
select 列名,列名,列名... from 表
- 查询商品名字和价格
select pname, price from product;
2.3 去重查询
- 语法
SELECT DISTINCT 字段名 FROM 表名; //要数据一模一样才能去重
- 去重查询商品的价格
select distinct price from product;
注意点: 去重针对某列, distinct前面不能先出现列名
2.4 别名查询
- 语法
select 列名 as 别名 ,列名 from 表 //列别名 as可以不写
select 别名.* from 表 as 别名 //表别名(多表查询, 明天会具体讲)
- 查询商品名称和商品价格,商品价格通过别名‘价格’来显示
select pname , price as 价格 from product;
2.5运算查询(+,-,*,/等)
- 把商品名,和商品价格+10查询出来
select pname ,price+10 from product;
select panme,price+num from product;
select pname,price+num 总价 from product;
注意
- 字符串可以运算但没有什么意义
- 字符串等类型可以做运算查询,但结果没有意义
3条件查询
3.1语法
select ... from 表 where 条件
//取出表中的每条数据,满足条件的记录就返回,不满足条件的记录不返回
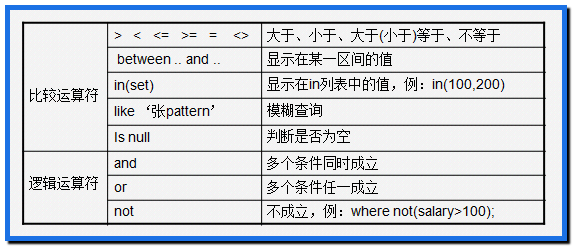
3.2between…and… 区间查询
eg: where price between 1000 and 3000 相当于 1000<=price<=3000
3.3 in(值,值…)
select * from t_product where id in(1,3,5,7)
3.4 like 模糊查询
一般和_或者%一起使用
- _ 占一位
- % 占0或者n位
name like '张%' --查询姓张的用户, 名字的字数没有限制
name like '张_' --查询姓张的用户 并且名字是两个的字的
3.5 and 多条件同时满足
where 条件1 and 条件2 and 条件3
3.6 or 任意条件满足
where 条件1 or 条件2 or 条件3
4排序查询
环境的准备
# 创建学生表(有sid,学生姓名,学生性别,学生年龄,分数列,其中sid为主键自动增长)
CREATE TABLE student(
sid INT PRIMARY KEY auto_increment,
sname VARCHAR(40),
sex VARCHAR(10),
age INT,
score DOUBLE
);
INSERT INTO student VALUES(null,'zs','男',18,98.5);
INSERT INTO student VALUES(null,'ls','女',18,96.5);
INSERT INTO student VALUES(null,'ww','男',15,50.5);
INSERT INTO student VALUES(null,'zl','女',20,98.5);
INSERT INTO student VALUES(null,'tq','男',18,60.5);
INSERT INTO student VALUES(null,'wb','男',38,98.5);
INSERT INTO student VALUES(null,'小丽','男',18,100);
INSERT INTO student VALUES(null,'小红','女',28,28);
INSERT INTO student VALUES(null,'小强','男',21,95);
4.1单列排序
- 语法: 只按某一个字段进行排序,单列排序
SELECT 字段名 FROM 表名 [WHERE 条件] ORDER BY 字段名 [ASC|DESC]; //ASC: 升序,默认值; DESC: 降序
- 练习: 以分数降序查询所有的学生
SELECT * FROM student ORDER BY score DESC
4.2组合排序
- 语法: 同时对多个字段进行排序,如果第1个字段相等,则按第2个字段排序,依次类推
SELECT 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名1 [ASC|DESC], 字段名2 [ASC|DESC];
- 练习: 以分数降序查询所有的学生, 如果分数一致,再以age降序
SELECT * FROM student ORDER BY score DESC, age DESC
5聚合函数
而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。聚合函数会忽略空值NULL
5.1 函数
| 聚合函数 | 作用 |
|---|---|
| max(列名) | 求这一列的最大值 |
| min(列名) | 求这一列的最小值 |
| avg(列名) | 求这一列的平均值 |
| count(列名) | 统计这一列有多少条记录 |
| sum(列名) | 对这一列求总和语法 |
5.2语法
SELECT 聚合函数(列名) FROM 表名 [where 条件];
5.3练习
-- 求出学生表里面的最高分数
-- 求出学生表里面的最低分数
-- 求出学生表里面的分数的总和(忽略null值)
-- 求出学生表里面的平均分
-- 统计学生的总人数 (忽略null)
-- 用 ifnull 不忽略null
SELECT MAX(score) FROM student
SELECT MIN(score) FROM student
SELECT SUM(score) FROM student
SELECT AVG(score) FROM student
SELECT COUNT(sid) FROM student
SELECT COUNT(*) FROM student
select avg(ifnull(score,0)) from student;
5.4注意:
聚合函数会忽略空值NULL.我们发现对于NULL的记录不会统计,建议如果统计个数则不要使用有可能为null的列,但如果需要把NULL也统计进去呢?我们可以通过 IFNULL(列名,默认值) 函数来解决这个问题. 如果列不为空,返回这列的值。如果为NULL,则返回默认值。
6分组查询
分组查询是指使用 GROUP BY语句对查询信息进行分组
GROUP BY将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用
3.1分组
- 语法
SELECT 字段1,字段2... FROM 表名 [where 条件] GROUP BY 列 [HAVING 条件];
- 练习:根据性别分组, 统计每一组学生的总人数
-- 根据性别分组, 统计每一组学生的总人数
SELECT sex, count(*) FROM student GROUP BY sex
3.2 分组后筛选 having
- 练习根据性别分组, 统计每一组学生的总人数> 5的(分组后筛选)
SELECT sex, count(*) FROM student GROUP BY sex HAVING count(*) > 5
3.3小结
group by 列 [having 条件]
-
注意事项
分组的目的一般为了做统计使用, 所以经常和聚合函数一起使用
分组查询如果不查询出分组字段的值(这句的意思是如果不select sex ),就无法得知结果属于那组
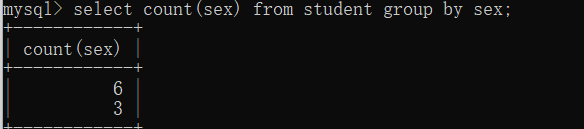
最好这样
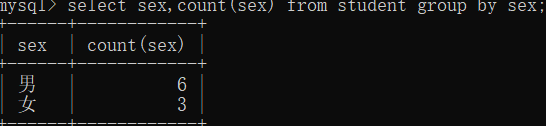
原理

就像这句 select sname,count(*) from student group by sex;

3where和having的区别【面试】
| 子名 | 作用 |
|---|---|
| where 子句 | 1) 对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,即先过滤再分组。2) where后面不可以使用聚合函数 |
| having字句 | 1) having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。2) having后面可以使用聚合函数 |
知识点-分页查询
1.目标
- 掌握分页查询
2.分析
LIMIT是限制的意思,所以LIMIT的作用就是限制查询记录的条数. 经常用来做分页查询
3.讲解
- 语法
select ... from .... limit 起始行数,查询的记录条数.
| LIMIT a,b; |
|---|
| a起始行数,从0开始计数,如果省略,默认就是0; a=(当前页码-1)*b; |
| b: 返回的行数 |
- 练习
eg: 分页查询学生, 每一页查询4条
b=4; a=(当前页码-1)*b;
第一页: a=0, b=4;
第二页: a=4, b=4;
第三页: a=8, b=4;
4.小结
- 语法
limit a,b;
a:从哪里开始查询, 从0开始计数 【a=(当前页码-1)*b】
b: 一页查询的数量【固定的,自定义的】
-
应用场景
如果数据库里面的数据量特别大, 我们不建议一次查询出来. 为了提升性能和用户体验, 使用分页
查询的语法小结
select...from...[where...][group by...having...][order by...][limit...]
select...from...
select...from...where...
select...from...order by...
select...from...group by...having...
select...from...limit...
总结
必须练习:
对记录的增删查改------------必须练习
- 能够理解数据库的概念
其实就是存储数据的仓库,可以持久化保存数据,并可以通过sql语句快速对数据进行增删查改
- 能够安装MySql数据库
查看资料中的文档
- 能够使用SQL语句操作数据库
对数据库的增
create database 数据库名;
对数据库的删
drop database 数据库名;
对数据库的查
show databases;
show create database 数据库名;
对数据库的改
alter database 数据库名 character set 字符集;
- 能够使用SQL语句操作表结构
对表的增
create table 表名(
字段名 字段类型 [字段约束],
字段名 字段类型 [字段约束],
...
字段名 字段类型 [字段约束]
);
字段类型:
数值类型: int,bigint,float,double
字符串: varchar(size),char(size)
时间日期:date,datetime
字段约束:
primary key 主键约束(唯一非空)
auto_increment 自增(int)
unique 唯一
not null 非空
对表的删
drop table 表名;
对表的查
show tables;
desc 表名;
对表的改
alter table 表名 add 字段名 字段类型 字段约束;
alter table 表名 modify 字段名 字段类型 字段约束;
alter table 表名 change 旧字段名 新字段名 字段类型 字段约束;
alter table 表名 drop 字段名 ;
rename table 旧表名 to 新表名;
- 能够使用SQL语句进行数据的添加修改和删除的操作
指定列添加:
insert into 表名(字段名,字段名,...) values(值,值,...);
添加所有列:
insert into 表名 values(值,值,...);
修改列:
update 表名 set 列名 = 值,列名=值 [where 条件];
删除:
delete from 表名 [where 条件];
truncate table 表名;
- 能够使用SQL语句进行条件查询数据
select...from 表 [where 条件][group by 列名][having 条件][order by 列名 asc\desc][limit a,b] []:可选
- 能够使用SQL语句进行排序
参考上面
- 能够使用聚合函数
avg(列名)
sum(列名)
max(列名)
min(列名)
count(列名)
- 能够使用SQL语句进行分组查询
参考上面
- 能够使用SQL语句进行分页查询
参考上面